
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Konfiguration
Atlassian Confluence REST Connector
Einleitung
Mithilfe des Atlassian Confluence REST Konnektors können Sie Ihre Confluence Cloud/Data Center Instanz an die Mindbreeze Suche anbinden. Somit können Sie ihre Confluence Spaces, Pages, Blogs, Attachments, Comments usw. in Mindbreeze Insight Apps nutzen.
Installation
Der Atlassian Confluence REST Konnektor ist bereits standardmäßig in Mindbreeze InSpire enthalten.
Konfiguration von Confluence Cloud
Konfiguration des Confluence Cloud Benutzers
Es wird ein Confluence‑Cloud‑Benutzer vorausgesetzt, der die Zugriffsberechtigung für alle Spaces und Pages besitzt, die in Mindbreeze InSpire verwendet werden sollen. Dieser Benutzer erzeugt dann ein API‑Token, das hauptsächlich Lese‑Berechtigungen auf die Confluence‑Cloud‑REST‑API hat.
Dieser Benutzer kann mit Mindbreeze USERNAME/PASSWORD Credentials, wobei das Passwort der generierte API-Token ist, verwendet werden.
Schritte zum Erzeugen des API-Tokens
- Melden Sie sich mit dem Confluence‑Cloud‑Benutzer unter https://id.atlassian.com/manage-profile/security an.
- Navigieren Sie zu „Create and manage API tokens“ und erstellen Sie einen Token.
(siehe Dokumentation: https://support.atlassian.com/atlassian-account/docs/manage-api-tokens-for-your-atlassian-account/) 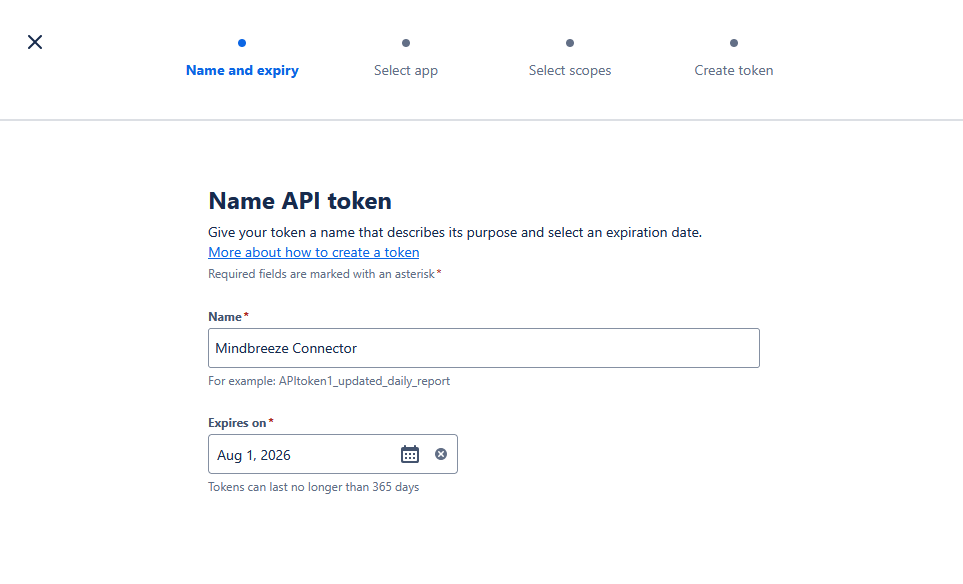
- Erstellen Sie den API‑Token und speichern Sie ihn für die spätere Konfiguration des Konnektors.
Hinweis: Stellen Sie sicher, dass der API‑Token regelmäßig erneuert wird, bevor er abläuft.
Konfiguration von Confluence Data Center
Konfiguration des Confluence Data Center Benutzers
Es wird ein Confluence DataCenter Benutzer mit Zugriffsrechten für alle Bereiche und Seiten benötigt, die in Mindbreeze InSpire verwendet werden sollen. Dieser Benutzer kann entweder mit Mindbreeze USERNAME/PASSWORD Credentials oder mit einem persönlichen Zugriffstoken in den Mindbreeze PASSWORD Credentials verwendet werden.
Schritte zum Erzeugen eines „Personal Access Token“
Anstelle von Benutzername und Passwort kann auch ein persönlicher Zugriffstoken zum Anmelden verwendet werden.
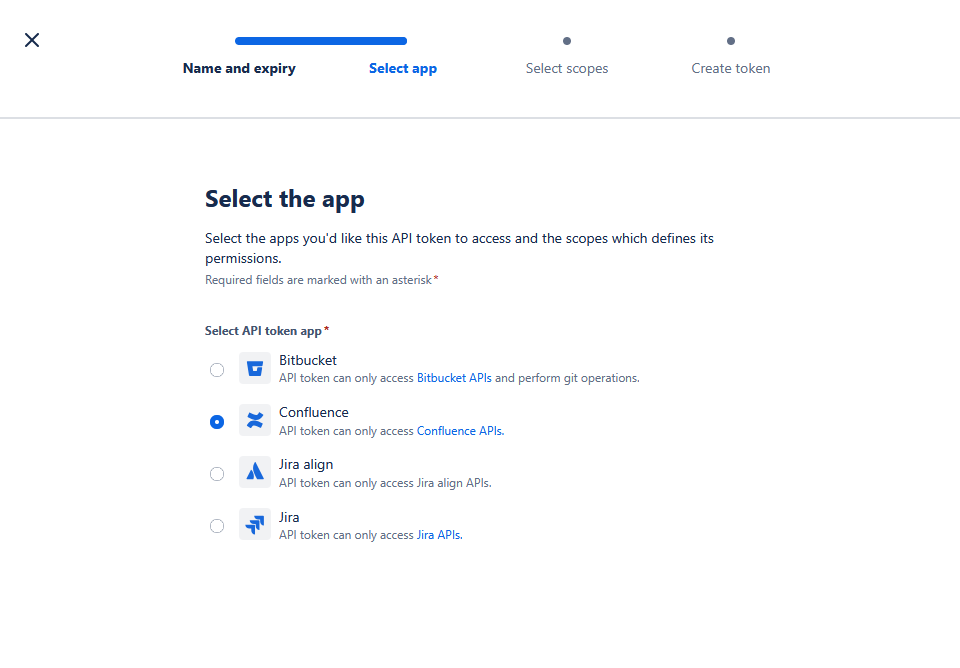
- Melden Sie sich mit dem Confluence-Data-Center-Benutzer in der Confluence-Umgebung an.
- Navigieren Sie zu den Benutzereinstellungen.
- Navigieren Sie zu den „Personal Access Tokens“ Einstellungen

- Generieren Sie einen neuen Token und verwenden Sie ihn als Mindbreeze PASSWORD Anmeldedaten:

Konfiguration von Mindbreeze
Öffnen Sie das Mindbreeze InSpire Management Center im Browser, um mit der Konfiguration zu beginnen.
Konfiguration des Index
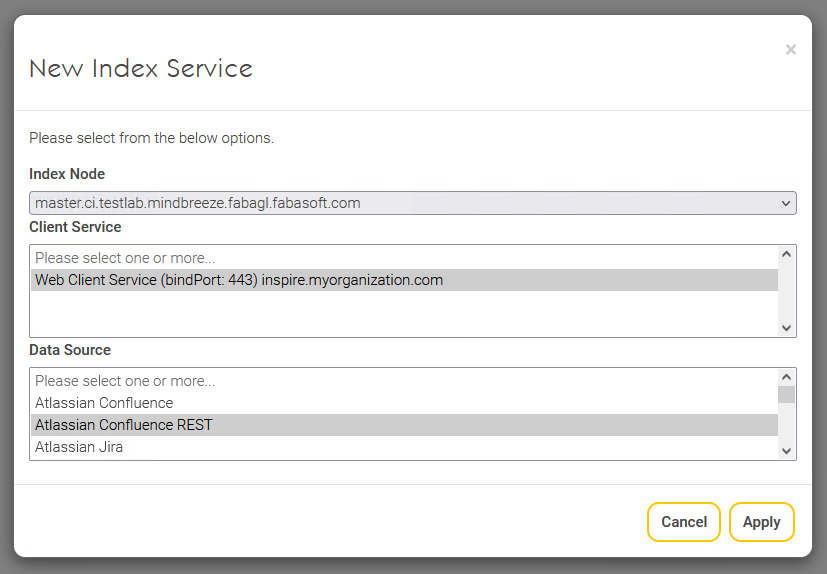
Fügen Sie im Tab „Indices“ mit dem Button „+Add Index“ einen neuen Index hinzu. Wählen Sie den gewünschten „Index Node“ und „Client Service“ aus und wählen Sie im Feld „Data Source“ die Datenquelle „Atlassian Confluence REST“ an. Bestätigen Sie Ihre Eingaben anschließend mit „Apply“:

Aktivieren Sie „Advanced Settings“ und ändern Sie folgende Einstellungen:
Eingabe | |
Use ACL References | Aktivieren |
Enable Precomputed ACLs | Force |
Konfiguration der Datenquelle
Konfigurieren Sie nun die Datenquelle.
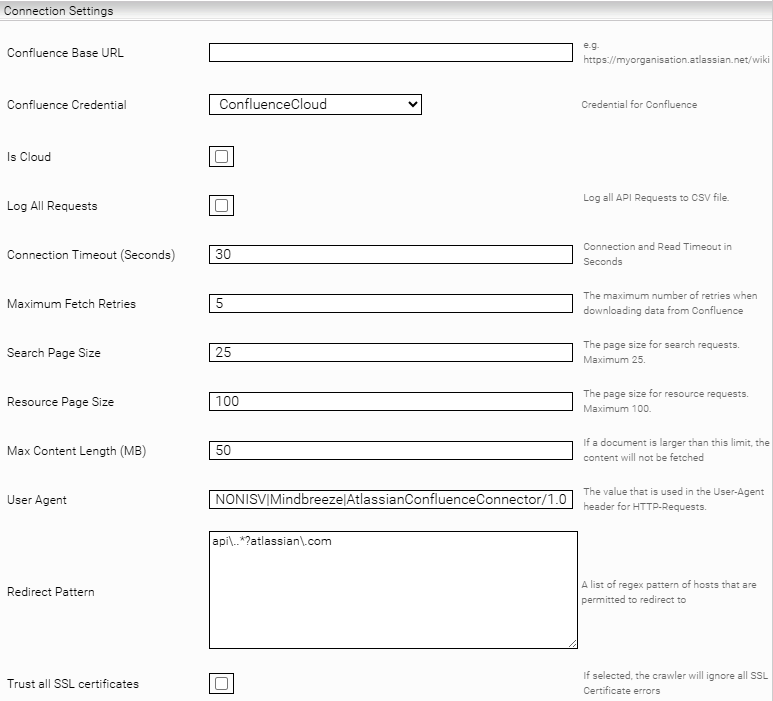
Connection Settings

Beschreibung | |||||||
Confluence Base URL* | Die URL zur Confluence Data Center Instanz im Format: | ||||||
Confluence Credential* | Das im „Network“-Tab erstellte Username/Password Credential. Hierfür müssen folgende Dinge konfiguriert werden:
| ||||||
Is Cloud | Wenn aktiviert, verarbeitet der Konnektor Confluence Cloud-Instanzen, andernfalls verarbeitet er DataCenter-Instanzen. | ||||||
Log All Requests | Wenn aktiviert, werden alle Requests an die Confluence‑API in eine Datei namens „request‑log.csv“ protokolliert. Kann bei einer Fehlersuche nützlich sein. | ||||||
Connection Timeout | Zeit in Sekunden, die auf eine Antwort gewartet werden soll, bevor der API-Call abgebrochen wird. | ||||||
Maximum Fetch Retries | Die maximale Anzahl an Retries, die versucht werden, wenn der Server gewisse Throttling‑Responses (z. B. 429) sendet. | ||||||
Search Page Size | Die Seitengröße, die für Suchanfragen an die API verwendet wird. Der Höchstwert beträgt 25. | ||||||
Resource Page Size | Die Seitengröße, die für Ressourcenanforderungen an die API verwendet wird. Der Höchstwert beträgt 100. | ||||||
Max Content Length (MB) | Wenn Dokumente die Größe (in MB) überschreiten, die in dieser Einstellung festgelegte wurde, werden sie mit leerem Inhalt indiziert. | ||||||
User Agent | User Agent Header, der für API-Calls verwendet wird. | ||||||
Redirect Pattern | Liste von Regex‑Mustern für erlaubte HTTP‑Redirects. | ||||||
Trust all SSL Certificates | Erlaubt die Verwendung von nicht gesicherten Verbindungen, beispielsweise für Testsysteme. Achtung: Darf nicht in der Produktionsumgebung aktiviert werden. | ||||||
* = Diese Einstellungen müssen zwingend konfiguriert werden, damit der Cache funktioniert und aufgebaut wird. Alle weiteren Einstellungen müssen je nach Anwendungsfall konfiguriert werden. | |||||||
Content Settings
Beschreibung | |||||||
Include Private Spaces | Wenn aktiviert, werden auch private Bereiche indiziert. | ||||||
Include Space Keys | Eine Liste von Bereichen, die indiziert werden sollen. Beachten Sie, dass pro Zeile nur ein Bereich-Key angegeben werden kann. | ||||||
Exclude Space Keys | Eine Liste von Bereichen, die nicht indiziert werden sollen. Beachten Sie, dass pro Zeile nur ein Bereich-Key angegeben werden kann.
Hinweis: Diese Einstellung kann nicht zusammen mit der Einstellung „Include Space Keys“ verwendet werden. | ||||||
Include Custom Property Pattern | Mit dieser Einstellung können Custom Content Properties indiziert werden. Es wird eine Liste von regulären Ausdrücken definiert, die auf den Namen der Custom Content Properties matchen. Übereinstimmende Properties werden indiziert. Beispielwerte:
Standardeinstellung: nicht gesetzt. | ||||||
Include Space Icons | Wenn aktiviert, werden die Bereichs Icons heruntergeladen. | ||||||
Include Comments | Wenn aktiviert, werden Kommentare indiziert. | ||||||
Include Attachments | Wenn aktiviert, werden Anhänge indiziert. | ||||||
Include Attachments Pattern | Steuert, welche Anhänge indiziert werden. Es wird eine Liste von regulären Ausdrücken definiert, die auf den Download‑URL‑Pfad gematcht werden. Beispiel für einen Download‑URL‑Pfad: /download/attachments/123456789/My Document.pdf Beispiel, um nur PDF‑Anhänge zu indizieren: | ||||||
Exclude Attachments Pattern | Steuert, welche Anhänge vom Indizieren ausgeschlossen werden sollen. Es wird eine Liste von regulären Ausdrücken definiert, die auf den Download‑URL‑Pfad gematcht werden.
Beispiel für einen Download‑URL‑Pfad: /download/attachments/123456789/My Document.pdf Beispiel, um PDF‑Anhänge zu exkludieren: | ||||||
Content Body Format | Das Format, in dem die API den Inhalt von Seiten und Blogbeiträgen zurückgibt.
| ||||||
Comment Body Format | Das Format, in dem die API den Inhalt von Kommentaren zurückgibt.
|
Security
Beschreibung | |
Enable Global Anonymous | Wenn Ihre Confluence‑Instanz den globalen anonymen Zugriff aktiviert hat (siehe Cloud Global Anonymous oder DC Global Anonymous), sollten Sie diese Einstellung aktivieren, damit Benutzer, die nicht eingeloggt sind, auch anonyme Dokumente in Mindbreeze finden können. |
Delete Documents | Wenn aktiviert, werden Dokumente, die in Confluence gelöscht werden, auch in Mindbreeze gelöscht. Hinweis: Es wird empfohlen, diese Einstellung auf Produktionssystemen immer aktiviert zu lassen. |
Konfiguration des Principal Resolution Service
Wählen Sie im neuen oder bestehenden Service in der Einstellung „Service“ die Option „Atlassian Confluence Principal Resolution Service“ aus.
Für mehr Informationen über das Erstellen, das grundlegende Konfigurieren eines Cache für einen Principal Resolution Service und weitere Konfigurationsoptionen, siehe Installation & Konfiguration - Caching Principal Resolution Service.
Die folgende Tabelle beschreibt die Einstellungen, die Sie beim Principal Resolution Service konfigurieren müssen. Je nach Anwendungsfall sind weitere Einstellungen optional verfügbar.
Damit der Principal Resolution Service für einen Benutzer die jeweiligen Projekt-Rollen oder Gruppen auflösen kann, muss die E-Mail-Adresse des Benutzers öffentlich sichtbar sein. Sie können das hier konfigurieren. Setzen Sie dafür die Spalte „Wer kann das sehen?“ auf „Jeder“ für die E-Mail-Adresse des Benutzers.
Connection Settings
Siehe: Connection Settings
Fehlerbehebung
Gruppen-Berechtigungen
Problem: Der folgende Fehler wird angezeigt:
ERROR: Found 200 group permissions for content 'Business Transaction Open'.
There might be more but they are skipped.
Lösung: Wenn eine Seite/ein Blogbeitrag mehr als 200 Gruppenbeschränkungen enthält, werden nur die ersten 200 abgerufen – die anderen werden übersprungen.
Dies wurde aufgrund einer Einschränkung der Confluence REST-API für DataCenter so konzipiert.
404-Fehlermeldung wird angezeigt, während Inhalte eines Bereiches iteriert werden
Problem: Der folgende Fehler wird angezeigt:
Failed to index all pages for space 'ABC'. Continuing with next space.
...
Error on requesting url: 'https://api.atlassian.com/ex/confluence/<<tenant-id>>/wiki/rest/api/search?next=true&cursor=...&expand=...&limit=5&start=25&cql=space+%3D+%22ABC%22+and+type+IN+%28blogpost%2C+page%29+order+by+lastModified+desc' status: 404 responseContent: '{"statusCode":404,"data":{"authorized":false,"valid":false,"errors":[{"message":{"translation":"No content with id <ContentId{id=123456789}> can be found","args":[]}}],"successful":false},"message":"com.atlassian.confluence.api.service.exceptions.NotFoundException: No content with id <ContentId{id=123456789}> can be found"}'
Dies geschieht in der Regel, wenn bereits „beschädigte“ Daten vom DataCenter in die Cloud migriert werden.
Anwendungsfall:
- Die Daten für Dokument XY werden abgerufen und um seine Vorgänger erweitert
(erforderlich für ACLs). - Die API geht davon aus, dass es einen Vorgänger für Dokument XY gibt, aber dieses Dokument existiert nicht mehr.
- Es wurde nicht aktiv gelöscht, da die API in diesem Fall leere (oder andere) Vorgänger zurückgeben würde und die 404-Fehlermeldung nicht ausgegeben würde.
- Die Antwort wird vom internen Suchalgorithmus von Confluence und nicht vom Crawler zurückgegeben.
Lösung:
Um saubere Crawl-Durchgänge zu gewährleisten, müssen diese Bereiche vom Crawling ausgeschlossen werden oder der Inhalt muss in Confluence korrigiert werden.
In der Regel lassen sich diese Seiten/Blogbeiträge leicht identifizieren, indem man in der Confluence-Benutzeroberfläche nachsieht, wo der übergeordnete Eintrag aufgeführt sein sollte, aber leer ist.
Ich kann Dokumente in Mindbreeze nicht finden (Confluence Data Center)
In Confluence Data Center-Instanzen kann ein Benutzer, der zur Standardgruppe confluence‑administrators gehört (als „Administrator“ bezeichnet), alle Seiten anzeigen, unabhängig von den in Confluence festgelegten Seitenberechtigungen.
Der „Administrator“ ist nicht in den Berechtigungseinträgen der Seite aufgeführt, dennoch kann der Benutzer die Seite über die Confluence-Benutzeroberfläche öffnen.
Mindbreeze ruft Confluence-ACLs über die REST-API ab. Da die API diesen Spezialfall bezüglich des „Administrators“ nicht offenlegt, kann es sein, dass derselbe Benutzer das Dokument bei der Suche in Mindbreeze nicht sieht.
Folge: Wenn eine Frage zu ACLs auftritt, überprüfen Sie zunächst, ob der betreffende Benutzer ein „Administrator“ ist. In Confluence Data Center können Administratoren mehr Inhalte sehen als die REST-API meldet.
Workaround: Erteilen Sie dem Administrator explizite Anzeigeberechtigungen für die relevanten Seiten in Confluence.
Empfehlung für Tests: Verwenden Sie für ACL-Such-Tests keine „Administrator“-Konten, sondern normale (Nicht-Admin-)Benutzer.
Meine Icons werden nicht indiziert (Cloud)
In Confluence Cloud-Instanzen gibt es bestimmte Umstände, unter denen Icons nicht heruntergeladen werden können.
Wenn der Crawl-Vorgang wie unten beschrieben fehlschlägt, handelt es sich wahrscheinlich um ein Problem, das mit einer Kombination aus drei Konfigurationseinstellungen zusammenhängt.
“Include Space Icons”
Bereichsbezogene API-Token
Aufgrund interner Weiterleitungen werden Symbole aus privaten Bereichen nicht über einen Standard-REST-API-Endpunkt abgerufen, sondern über „https://api.atlassian.com/ex/confluence/<<cloudID>>/wiki/aa-avatar/<<userID>>”.
Dadurch kann der Token nicht korrekt validiert werden und es ist nicht möglich, Symbole aus privaten Bereichen herunterzuladen.
Caused by: com.mindbreeze.enterprisesearch.mesapi.util.net.HttpClientException$HTTP401Unauthorized: Error on requesting url: 'https://api.atlassian.com/ex/confluence/dfe9338a-4999-4ad1-a347-b9ce7780beed/wiki/aa-avatar/62c6c0cdefb17d6ce62fb56e' status: 401 responseContent: '{"code":401,"message":"Unauthorized; scope does not match"}'
Folge: Space-Symbole aus privaten Bereichen können nicht mit einem bereichsbezogenen Token heruntergeladen werden, sondern nur mit einem „normalen“ Token.
Workaround: Verwenden Sie einen „normalen“ API-Token anstelle eines bereichsbezogenen API-Tokens.
Meine Icons werden noch immer nicht indiziert
Wenn die Icons immer noch nicht indiziert werden, überprüfen Sie die Logs auf Fehlermeldungen – möglicherweise gibt es eine Ausnahme wie diese:
Caused by: com.mindbreeze.enterprisesearch.connectors.commons.crawlerbase.http.HTTP300Exception: Error on requesting url: 'https://api.atlassian.com/ex/confluence/dfe9338a-4999-4ad1-a347-b9ce7780beed/wiki/aa-avatar/62c6c0cdefb17d6ce62fb56e' status: 302 responseContent: ''
Zum Herunterladen des Bildes werden mehrere Weiterleitungen durchgeführt. Alle zusätzlichen Hosts, zu denen die Weiterleitungen erfolgen, müssen in der erweiterten Konfigurationsoption “Redirect Pattern” auf die Whitelist gesetzt werden.
Häufige/bekannte Hosts sind:
secure.gravatar.com
i0.wp.com