
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Konfiguration
Filter Plugins
Einleitung
Im Bereich „Filter Plugins“ der Filter Service Konfiguration sind alle installierten Filter Plugins, die für eine Datei-Erweiterung ausgewählt werden können, verfügbar. Die Erweiterungen werden ohne Berücksichtigung der Groß-/Kleinschreibung abgeglichen.
Im Bereich „Global Filter Plugin Properties“ können diese Filter Plugins konfiguriert werden, wenn eine spezielle Konfiguration benötigt wird. Dazu sollte das entsprechende Plugin von der Drop-Down-Liste ausgewählt und zu der Filterkonfiguration hinzugefügt werden.
Allgemeine Plugin-Einstellungen
Das folgende Feld kann für mehrere Plugins konfiguriert werden.
Number of instances | Legt fest, wie viele Instanzen des Plugins parallel laufen sollen. Standardwert: Lassen Sie das System entscheiden. |
Allgemeine Informationen zu Standard Email Filter (FilterPlugin.POIMsg und FilterPlugin.EML)
E-Mails (Dokumente mit Extension .msg oder .eml) beinhalten üblicherweise mehrere Inhalte. Beispiele für diese Inhalte sind E-Mail Anhänge. Die Standard Email Filter Plugins (FilterPlugin.POIMsg und FilterPlugin.EML) extrahieren E-Mail Anhänge aus den E-Mail Dokumenten. Je nach Extension werden die Anhänge anschließend an andere Filter weitergeleitet (z.B. PDF, DOCX…) welche die weitere Extraktion des Inhalts vornehmen.
Der Inhalt eines E-Mails kann auch in verschiedenen Formaten (teilweise sogar nebeneinander) vorliegen. Beispiele sind Plaintext- (TXT), HTML- oder Richtext- (RTF) und HTML-Format E-Mails. Wenn vorhanden, wird HTML bevorzugt und an den für HTML konfigurierten Filter weitergeleitet. Ansonsten wird RTF oder TXT als Inhalt verwendet.
Die einzelnen Teile von E-Mails (Anhänge, Inhalte) werden auch als MIME-Parts bezeichnet. Diese MIME-Parts können je nach E-Mail Anwendung, Betriebsystem und Standorteinstellungen verschiedene Character Encodings innerhalb desselben E-Mails besitzen. Die Standard Email Filter (FilterPlugin.POIMsg und FilterPlugin.EML) normalisieren diese Character Encodings auf UTF-8. Dieses Verhalten lässt sich bei Bedarf auch anpassen.
FilterPlugin.POIMsg
Folgende Felder können für POIMsg Filter Plugin konfiguriert werden:
Feldname | Beschreibung |
Keep Datasource Category Class | Standardmäßig bekommen alle msg Dateien die Category Class „mail“, auch wenn die Datenquelle eine andere Category Class definiert. Um die Category Class von der Datenquelle beizubehalten sollte dieses Feld ausgewählt werden. |
Prefer HTML Meta Tag Character Encoding | Wenn aktiviert, wird der HTML-Inhalt von E-Mails mit dem Character Encoding, welches im HTML meta tag angegeben ist, geparst. Dadurch wird das Character Encoding, welches im MIME-Part angegeben ist, nicht durchgeführt. Standardeinstellung: Deaktivert. |
FilterPlugin.InternalZip
Folgende Felder können für InternalZip Filter Plugin konfiguriert werden:
Feldname | Beschreibung | ||||||
Datasource Metadata Selection Strategy | Die folgenden Optionen stehen zur Verfügung:
|
FilterPlugin.EML
Folgende Felder können für EML Filter Plugin konfiguriert werden:
Beschreibung | |
Prefer HTML Meta Tag Character Encoding | Wenn aktiviert, wird der HTML-Inhalt von E-Mails mit dem Character Encoding, welches im HTML meta tag angegeben ist, geparst. Dadurch wird das Character Encoding, welches im MIME-Part angegeben ist, nicht durchgeführt. Standardeinstellung: Deaktivert. |
Keep MIME Part Character Encoding | Wenn aktiviert, werden die Text- und HTML-Inhalte nicht auf UTF-8 normalisiert, sondern bleiben im ursprünglichen Format. Standardeinstellung: Deaktivert. |
FilterPlugin.MetadataOnly
Der FilterPlugin.MetadataOnly dient als Fallback-Filter, wenn kein anderer Filter das Dokument filtern konnte und "Probing" aktiviert ist. Mit diesem Filter ist es möglich, Dokumente zu indizieren, die mit anderen Filtern nicht indiziert werden können.
Das FilterPlugin.MetadataOnly reicht Dokumente an den Index weiter, ohne den Inhalt selbst zu filtern. Das bedeutet, dass keine inhaltlichen Metadaten sowie keine Vorschau für das Dokument erstellt werden. Metadaten wie Dateiname, Datum, Autor etc. werden trotzdem an den Index übergeben.
Dieser Filter kann beispielsweise verwendet werden, um verschlüsselte PDF-Dateien zu indizieren. Ohne dieses Plugin (und ohne aktiviertes „Probing“) werden verschlüsselte PDF-Dateien vom Filter verworfen und nicht an den Index weitergeleitet, da der Filter keinen Zugriff auf den Inhalt des PDFs hat. Wenn dieser Filter und "Probing" für die gewünschte Dateierweiterung aktiviert ist, filtert der gewählte PDF-Filter wie gewohnt unverschlüsselte PDF-Dateien weiter. Verschlüsselte PDF-Dateien werden stattdessen durch den MetadataOnly-Filter verarbeitet und können in der Suche gefunden werden, allerdings ohne Inhalt.
Standardmäßig ist dieser Filter für alle Dateierweiterungen aktiviert, die standardmäßig aktiviert sind (z.B.: HTML, txt, pdf etc.) verarbeitet aber nur Objekte, wenn auch „Probing“ für die gewünschten Erweiterungen aktiviert ist. Für alle nicht standardmäßig aktivierten Erweiterungen muss der Filter manuell aktiviert werden, indem er ausgewählt wird.
Folgende Felder können für das MetadataOnly Filter Plugin konfiguriert werden:
Feldname | Beschreibung |
Is enabled | Kann verwendet werden, um den Filter zu deaktivieren. Standardeinstellung: Aktiviert. |
FilterPlugin.PDFPreviewFPDFFilter
Das FilterPlugin.PDFPreviewFPDFFilter wird verwendet, um Metadaten und Inhalte aus PDF-Dokumenten zu extrahieren.
Die folgenden Felder können für das PDFPreviewFPDFFilter-Plugin konfiguriert werden:
Feldname | Beschreibung |
Disable Thumbnails | Wenn diese Option aktiviert ist, wird die Erstellung eines Thumbnail für das Dokument deaktiviert. Standardeinstellung: False (Miniaturansichten werden erstellt). |
Disable Preview Content | Wenn diese Option aktiviert ist, wird die Erstellung einer vollständigen Vorschau des PDF-Dokuments aus den Suchergebnissen deaktiviert. In diesem Fall wird in der Vorschau nur eine Zusammenfassung des Inhalts angezeigt. Standardeinstellung: False (vollständige Vorschauen sind verfügbar). |
Extract Links | Wenn diese Option aktiviert ist, extrahiert der Filter das Ziel von externen Links in PDF-Dokumenten. Wenn die HTML Entity Recognition für HTML-Links aktiv ist (siehe <>), werden auch Entities extrahiert. Standardeinstellung: Deaktiviert |
Max Layout Annotations Per Page | Maximale Anzahl der als Annotation zu extrahierenden Textfelder pro Seite. Standardwert: 0Default value: 0 |
Thumbnail Width | Maximale Breite des Thumbnails (in Punkt). Hinweis: Das Seitenverhältnis der Seite bleibt erhalten. Geben Sie nicht gleichzeitig eine maximale Höhe und eine maximale Breite an. Standardwert: 200pt |
Thumbnail Height | Maximale Höhe des Thumbnails (in Punkten) Hinweis: Das Seitenverhältnis der Seite bleibt erhalten. Geben Sie nicht gleichzeitig eine maximale Höhe und eine maximale Breite an. Standardwert: 200pt |
PDF Meta Keys (in Addition to Defaults) | Zusätzliche zu extrahierende PDF-Metadaten, getrennt durch Semikolons. Standard-Metadaten (title, author, subject, keywords, creator, producer, creation date, modification date) werden standardmäßig extrahiert, es ist nicht notwendig, sie hinzuzufügen. Standardwert: Keine |
Die Größen werden in Punkten angegeben (1 Punkt = 1/72 Zoll = ca. 0,3528 mm).
FilterPlugin.OfficeDocumentToPDFContentFilter
Mit dem Filter Plugin „OfficeDocumentToPDFContentFilter“ werden Microsoft Office Dokumente für die PDF-Vorschau vorbereitet.
Dieses Filter-Plugin ist standardmäßig deaktiviert bzw. muss explizit aktiviert werden.
Das Filter Plugin kann auf folgende Dateiendungen angewandt werden:
Dateiendung | |
Microsoft Word, LibreOffice Writer oder Google Text und Tabellen | odt |
LibreOffice Writer | sxw |
LibreOffice-Suite |
|
ArcScene | sxd |
Microsoft Windows Wordpad, Mac Textedit | rtf |
Microsoft Word |
|
Microsoft PowerPoint |
|
Microsoft Excel |
|
Microsoft Visio |
|
Steinberg Cubase, Imageline FL Studio und Audacity | vst |
Folgende Einstellungen stehen zur Verfügung:
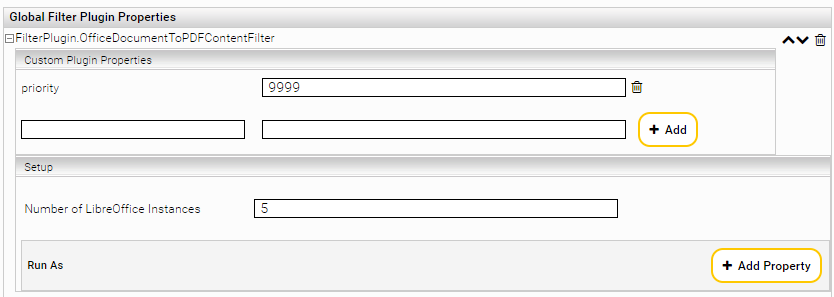
Beschreibung | Beispiel | |
Custom Plugin Properties | ||
priority | Gibt die Reihenfolge an in der die Plugins ausgeführt werden. Je höher die angegebene Zahl ist, umso höher ist die Priorität und umso früher wird das Plugin ausgeführt. Die Nutzung dieser Einstellung wird für Anwendungsfälle empfohlen, wo die Anwendung von verschiedenen Plugins auf verschiedene Dateiformate im Detail gesteuert werden soll. | 1947 |
Setup | ||
Number of LibreOffice Instances | Definiert die Anzahl der Instanzen, die gestartet werden sollen. Wenn nicht gesetzt, wird ein Standard Wert angenommen, der im allgemeinen Fall ausreichend ist. | 3 |
Run as | ||
User name | Diese Einstellung wird nicht mehr verwendet. | - |
Password | Diese Einstellung wird nicht mehr verwendet. | - |
PDF-Vorschau für alle verfügbaren Dateitypen aktivieren
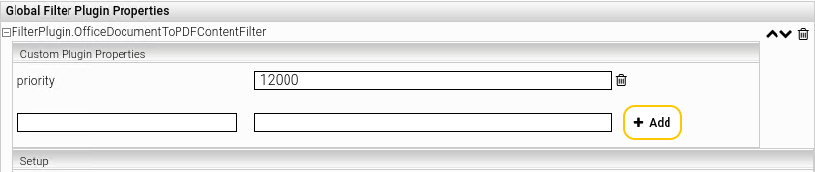
Standardmäßig wird das Filter-Plugin „FilterPlugin.ApacheTikaWithThumbnails-Latest“ für Microsoft Office Dokumente verwendet. Um das Filter-Plugin „FilterPlugin.OfficeDocumentToPDFContentFilter“ vorzureihen und dadurch eine PDF-Vorschau zu erzeugen, muss die Priorität des FilterPlugin.OfficeDocumentToPDFContentFilter auf einen Wert größer als 11100 gesetzt werden. Dies kann man in der Einstellung „priority“ konfigurieren:
PDF-Vorschau für einen oder mehrere Dateitypen aktivieren
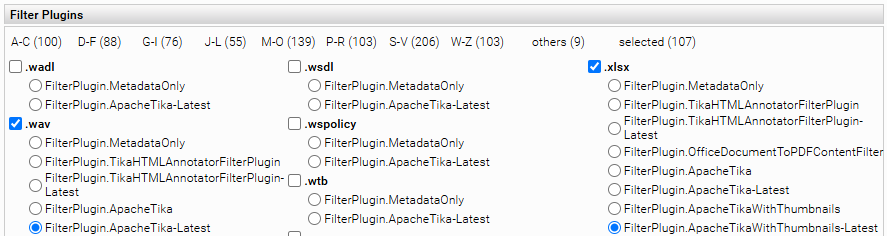
Um die PDF-Vorschau für einen oder mehrere bestimmte Dateitypen zu aktivieren, kann man in den Filtereinstellungen das Filter-Plugin „FilterPlugin.OfficeDocumentToPDFContentFilter“ für einen bestimmten Dateitypen aktivieren (siehe Dateiendung xlsx im Screenshot):
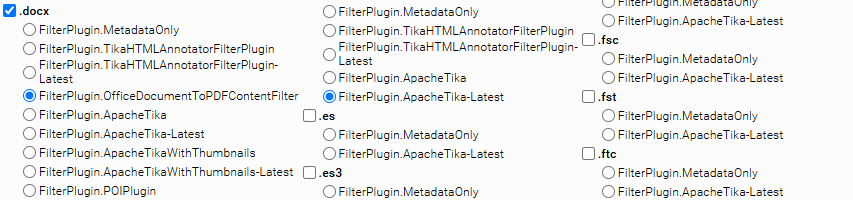
Zum Beispiel können Sie mit einem Klick das Filter-Plugin „FilterPlugin.OfficeDocumentToPDFContentFilter“ für die Dateiendung .docx auswählen:
FilterPlugin.Pandoc
Das FilterPlugin.Pandoc wird verwendet, um Inhalte aus Microsoft-Office-Dokumenten zu extrahieren.
Dieses Filter-Plugin ist standardmäßig deaktiviert bzw. muss explizit aktiviert werden.
Das Filter Plugin kann auf folgende Dateiendungen angewandt werden:
Dateiendung | |
Microsoft Word, LibreOffice Writer oder Google Text und Tabellen | odt |
Microsoft Windows Wordpad, Mac Textedit | rtf |
Microsoft Word | docx |
Microsoft PowerPoint | pptx |
Microsoft Excel | xlsx |