Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Whitepaper
Web Connector: Erweiterte JavaScript Anwendungsfälle
Einleitung
Der Web Konnektor indiziert HTML-Dokumente und unterstützt mithilfe des „JavaScript Crawlings“ auch das Indizieren von Webseiten, welche JavaScript verwenden.
In dieser Dokumentation wird der Umgang und die Handhabung mit dem JavaScript Crawling im Zusammenhang mit erweiterten JavaScript Anwendungsfällen beschrieben.
Hinweis: Für die hier beschriebenen Anwendungsfälle sind Grundkenntnisse mit dem Umgang vom HTML und JavaScript erforderlich. Weiters sind Basiskenntnisse über den Aufbau der zu indizierenden Webseite notwendig.
Architektur
Web Konnektor ohne JavaScript (Reguläres Web-Crawling)
Der Web Konnektor lädt die zu indizierenden Webseiten in diesem Modus direkt mittels eines einzigen HTTP Requests herunter. In diesem Modus ist es dem Konnektor nicht möglich, Webseiten mit dynamischen Inhalten richtig zu indizieren.
Web Konnektor mit JavaScript (JavaScript-Crawling)
Der Web Konnektor lädt in diesem Modus die zu indizierenden Webseiten indirekt mittels JavaScript-Crawling herunter und ermöglicht es so auch Webseiten zu indizieren, die dynamisch mit JavaScript geladen werden.
Dieser Modus ist allerdings sehr leistungsaufwändig und sollte nur verwendet werden, wenn keine bessere Alternative zu Verfügung steht. Siehe Sektion 3.1.1
Für JavaScript-Crawling sind einige zusätzliche Einstellungen notwendig, die in den folgenden Abschnitten beschrieben werden.
Vergleich zwischen Regulärem Web-Crawling und JavaScript-Crawling
Die folgende Tabelle zeigt die wichtigsten Eigenschaften und Unterschiede zwischen regulärem Web-Crawling und JavaScript-Crawling.
Webinhalte Kompatibilität | Reguläres Web-Crawling | JavaScript-Crawling |
Crawling-Effizienz | Hocheffizient | Sehr leistungsaufwändig |
Statische Webseiten | Werden vollständig indiziert | Werden vollständig indiziert |
Webseiten mit Authorisierung (die im regulären Crawling nicht unterstützt sind) | Werden mit Login-Maske indiziert, Indizierung nicht vollständig möglich | Automatisches Login ist möglich, um nur Inhalt zu indizieren |
Webseiten mit ungewollten Inhalten (Statische Cookie-Banner oder Werbung) | Ungewollten Inhalt wird indiziert | Ungewollter Inhalt kann versteckt werden |
Inhalte, die durch User-Input geladen werden | Manche Inhalte werden nicht geladen | User-Input kann simuliert werden. Alle Inhalte werden geladen und indiziert. |
Inhalte, die verzögert (lazy) geladen werden | Manche Inhalte werden nicht geladen | Der Crawler kann auf Inhalte warten. Alle Inhalte werden indiziert. |
Konfiguration JavaScript-Crawling
Einstellungen zur Indizierung mit JavaScript
Mit den folgenden Einstellungen kann reguliert werden, ob und welche Seiten mit JavaScript indiziert werden sollen. Weiters kann auch reguliert werden, ob nur Webseiten mit dem Content-Typ „text/html“ indiziert werden sollen (dieser wird in einem separaten HEAD-Request ermittelt).
Eine ausführliche Erklärung zu den unten aufgeführten Einstellungen können in der Dokumentation Konfiguration - Web Connector nachgelesen werden.
- Enable JavaScript
- Skip Head Request
- Include JavaScript URL (regex)
- Exclude JavaScript URL (regex)
Die Idee hinter dieser feingranularen Konfigurationsmöglichkeiten ist es, JavaScript-Crawling selektiv nur für die Webseiten einzusetzen, für die es notwendig ist.
Standardverhalten
Wenn der Web Konnektor im JavaScript Modus betrieben wird (ohne weitere Einstellungen zu konfigurieren), wird der Webseiteninhalt geladen und wird indiziert sobald der eingestellte „Page Ready State“ erreicht ist. Falls der eingestellte „Page Ready State“ nicht innerhalb des „Network Timeouts“ erreicht wurde, wird ein Fehler geloggt und der Inhalt nicht indiziert.
Auch diese Einstellungen können hier nachgelesen werden.
Verhalten mit Scripts
Scripts sind JavaScript Code Fragmente, die für erweiterte Anwendungsfälle konfiguriert werden können. In den folgenden Abschnitten wird der Umgang mit Scripts beschrieben.
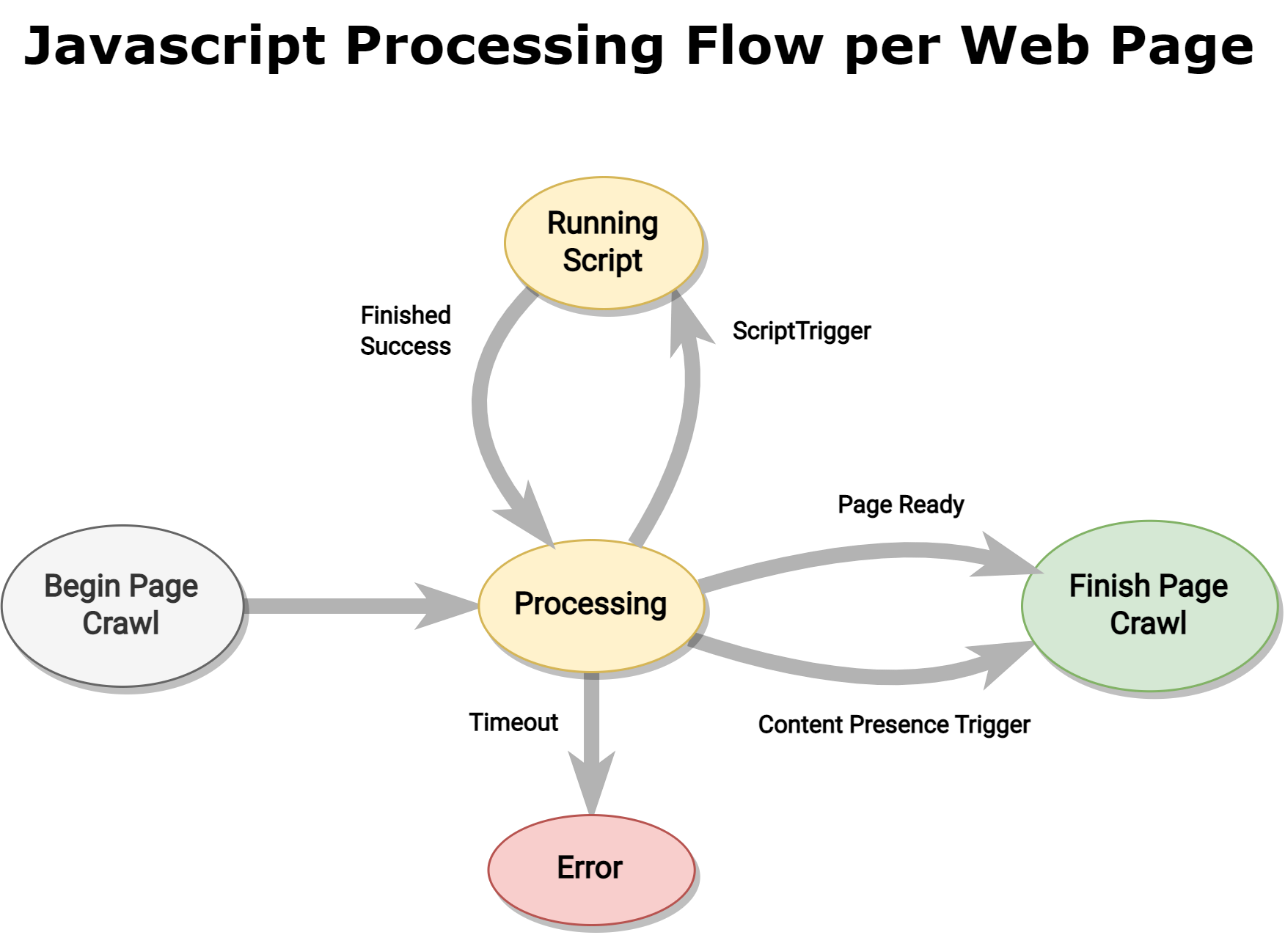
JavaScript Ablauf mit Skripts
Wenn JavaScript-Fragmente ausgeführt werden, folgt der Programmablauf immer dem gleichen Muster das nur durch bestimmte Bedingungen unterbrochen wird. Das folgende Diagramm zeigt diesen Ablauf.
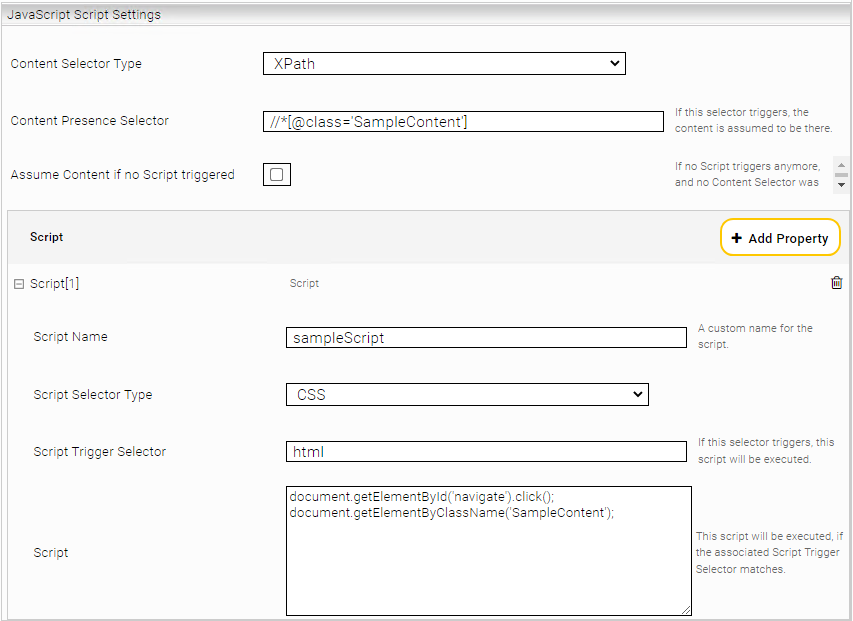
Content Presence Selector
Wenn das Standardverhalten des Konnektors nicht ausreichend ist, (Beispielsweise wird eine Webseite nur mit unvollständigem Inhalt indiziert) ist es möglich einen „Content Presence Selector“ zu definieren. Dieser Selektor kann mittels XPath oder CSS-Selektoren angegeben werden und ändert die Bedienung zum Erkennen des Inhalts, sodass nun auf den Selektor gewartet wird. Dies eignet sich besonders für komplexe Webseiten, die länger zum Laden brauchen.
Für den Fall, dass verschiedene Websites mit unterschiedlichen Anwendungsfällen genutzt werden, kann für jeden Content Presence Selector ein oder mehrere URL-Patterns definiert werden. Diese Patterns legen fest, bei welchen URLs der Content Presence Selector ausgelöst werden kann.
Scripts
Bei Webseiten, die z. B. Benutzereingaben brauchen oder komplexer aufgebaut sind, kann der Content Presence Selector mit der Einstellung Script erweitert werden.
Konfigurierte Skripts werden ereignisbasiert mithilfe von Script Trigger Selectoren ausgeführt. Außerdem werden Skript-Trigger-Selektoren nur dann überprüft, wenn die aktuelle URL mit den URL-Regex-Patterns (bei normalen Skripten) oder den erlaubten Hostnamen (bei Credential-Skripten) übereinstimmt.
Script Trigger Selector
Ein Script Trigger Selector prüft im DOM des Dokuments, ob eine bestimmte Bedingung eintritt. Sobald ein Script Trigger Selector auslöst, wird das zugehörige Script im Kontext der aktuellen Verarbeitung der Webseite ausgeführt.
Die Verarbeitung stoppt, wenn der „Content Presence Selector“ aktiv wird (wenn der gesuchte Inhalt geladen wurde).
Beispielsweise kann ein Script Trigger Selector erkennen, ob aktuell eine Benutzereingabe notwendig ist (z.B. ein Anmeldeformular wird angezeigt) und führt dann im zugehörigen Script Aktionen aus (z.B. ein Klick auf den Anmeldeknopf)
Diese Script Trigger Selectoren können mittels XPath und CSS angegeben werden.
Skript-Arten
Der Zweck eines Skripts besteht hauptsächlich darin, grundlegende Aktionen wie Scrollen, Schließen von Cookie-Bannern usw. auszuführen. Skripts dieser Art können entsprechend dem Anwendungsfall angepasst werden.
Credential-Skript
Ein Credential Script ist ein normales Skript, das einige Sicherheitsverbesserungen beinhaltet:
- Für jedes Credential-Skript kann ein Credential ausgewählt werden, das dann im Skript verwendet wird. Das bedeutet, dass ein Passwort nicht im Klartext in das Skript geschrieben werden muss. Credentials können mithilfe des mesCredential-Objektes folgendermaßen im Skript verwendet werden:
- mesCredential.password
- mesCredential.username
- mesCredential.domain
Einschränkungen
Es dürfen keine Skripts angegeben werden, bei denen in einer Schleife Inhalt geladen wird. Skripts werden single threaded ausgeführt und blockieren im Falle einer Schleife jegliche Aktionen vom Browser (Beispiel Anwendungsfall: Unendliches Scrollen)
Wenn ein Skript sehr oft und über einen längeren Zeitraum ausgeführt werden soll (scrollen) muss darauf geachtet werden, dass sowohl das „Network Timeout“ als auch das „Page Load Timeout“ hoch genug ist.
Es dürfen keine Listener in den Skripts verwendet werden, da der Kontext zwischen den einzelnen Skriptausführungen verloren geht.
Assume Content if no Script triggered
In manchen Fällen gibt es keinen eindeutigen Content Presence Selector. Dies kann der Fall sein, wenn Elemente des Inhalts bereits in das DOM geladen wurden, bevor das Skript ausgeführt wurde.
Für diese spezielle Fälle gibt es die Einstellung „Assume Content if no Script triggered“. Wenn diese Einstellung gesetzt ist, wird die Verarbeitung gestoppt, sobald kein einziger Script Trigger Selector mehr aktiv ist und die Webseite wird in diesem Zustand indiziert.
Hinweis: Bei Webseiten deren Inhalte verzögert geladen werden, ist Vorsicht geboten, da diese Einstellung dazu führen kann, dass nachfolgende Scripts nicht mehr ausgeführt werden und der Inhalt möglicherweise vorzeitig und unvollständig Indiziert wird.
Anwendungsfälle
Intranet mit nicht unterstützter API Authentifizierung
In diesem Beispiel wird erklärt, welche Schritte für die Einrichtung des Mindbreeze Web Konnektors zum Crawlen einer Intranet-Webseite mit (im regulären Crawling) nicht unterstützter API Authentifizierung notwendig sind.
Anforderungsanalyse
Alternativen
Die zu indizierende Webseite muss zunächst analysiert werden. Nachdem das Indizieren mit JavaScript sehr leistungsaufwendig ist, sollten zuerst folgende Fragen beantwortet werden:
- Gibt es für die relevante Webseite einen bestehenden Konnektor?
(e.g.: Microsoft Sharepoint Online-, Salesforce-, Google Drive-, Box Connector) - Wird die Authentifizierungsvariante bereits mit regulärem Crawling unterstützt? (Form, Basic, NTLM, OAuth)
- Gibt es eine API, die mithilfe des Data Integration Konnektors integriert werden kann?
Siehe Konfiguration - Data Integration Connector
Falls für die Webseite keine der oben genannten Alternativen existiert, fahren wir mit dem JavaScript-Crawling fort. Der nächste Schritt ist die Analyse des Verhaltens der Website.
Verhalten
Um das Verhalten der Webseite analysieren zu können, muss zuerst sichergestellt werden, dass die nötigen Anmeldedaten (Benutzername, Passwort) vorhanden sind und dass die Anmeldung mit einem Browser (z.B.: Chrome, Firefox) funktioniert.
Nachdem die Anmeldung im Browser erfolgreich war, stellen Sie sicher, dass alle zu indexierenden Inhalte zugänglich sind. (Möglicherweise hat der Benutzer nicht ausreichend Berechtigungen, um die relevanten Inhalte zu sehen)
Wenn alle Inhalte korrekt angezeigt werden, werden die einzelnen Seiten im Detail analysiert.
Für die Analyse der einzelnen Seiten muss zwischen drei Arten unterschieden werden:
- Login Seiten
- Inhaltsseiten
- Weiterleitungen („Weitergeleitete Seiten“)
Login Seiten
- Wie ist das Login-Formular aufgebaut, welche Felder müssen ausgefüllt werden?
- Wie wird der Login ausgelöst? Welcher Knopf muss betätigt werden?
- Wie lange dauert der gesamte Login-Vorgang? (evtl. müssen Timeouts angepasst werden)
- Zu welche Hosts werden Verbindungen aufgebaut (z.B. laden von Schriftarten oder JavaScript Komponenten von anderen Servern)?
Hinweis: 2-Faktor-Authentifizierungen können NICHT unterstützt werden.
Inhaltsseiten
Die Inhaltsseiten repräsentieren die Seiten, die indiziert werden sollen. Hier gilt zu analysieren wie der Inhalt aufgebaut ist.
Folgende Punkte sind hier zu beachten:
- Sind Aktionen vom Benutzer notwendig, um den Inhalt zu sehen? z.B.:
- Muss hinunter gescrollt werden damit der ganze Inhalt geladen wird?
- Muss ein Knopf gedrückt werden um den Inhalt anzuzeigen?
- Muss eine Eingabe oder Bestätigung erfolgen damit der Inhalt angezeigt wird? (z.B. Cookie-Banner)
- Muss ein Menü bedient werden?
- Wie schnell reagiert die Seite auf diese Aktionen (eventuell müssen Timeouts angepasst werden)?
- Zu welchen Hosts werden Verbindungen aufgebaut (z.B. Laden von Schriftarten oder JavaScript Komponenten von anderen Servern)?
- Mehr Informationen dazu finden Sie unter „Weitergeleitete Seiten“.
Weiterleitungen (Weitergeleitete Seiten)
Bei Webseiten, die auf andere Seiten weiterleiten, muss beachtet werden, dass der Web Konnektor standardmäßig aus Sicherheitsgründen alle unbekannten Hosts blockiert. (Fehlercode BLOCKED_BY_CLIENT)
Um andere Hosts zuzulassen müssen diese als „Additional Network Resources Hosts“ in den Einstellungen angegeben werden.
Hinweis: Dies gilt auch für Sitemaps. Hier müssen alle relevanten Hosts als „Additional Network Resources Hosts“ angegeben werden.
Browser Developer Konsole
Wenn die Analyse dieser Seiten abgeschlossen ist kann nun begonnen werden die Anmeldung mittels JavaScript in der Developer Konsole des Browsers (F12) nachzustellen.
Login Seite
Der erste Schritt besteht darin, die Elemente des Login Fensters (z.B.: Username, Password, Anmelde-Knopf) zu lokalisieren und den entsprechenden Selektor zu notieren.
Für die Login Seite eignet sich der Selektor für das Formular sehr gut als „Script Trigger Selector“ jedoch können mit XPath auch komplexere Selektoren angegeben werden, die beispielsweiße die Kombination aus Benutzername und Passwort ID suchen.
(//*[@id='username'] and //*[@id='password'])
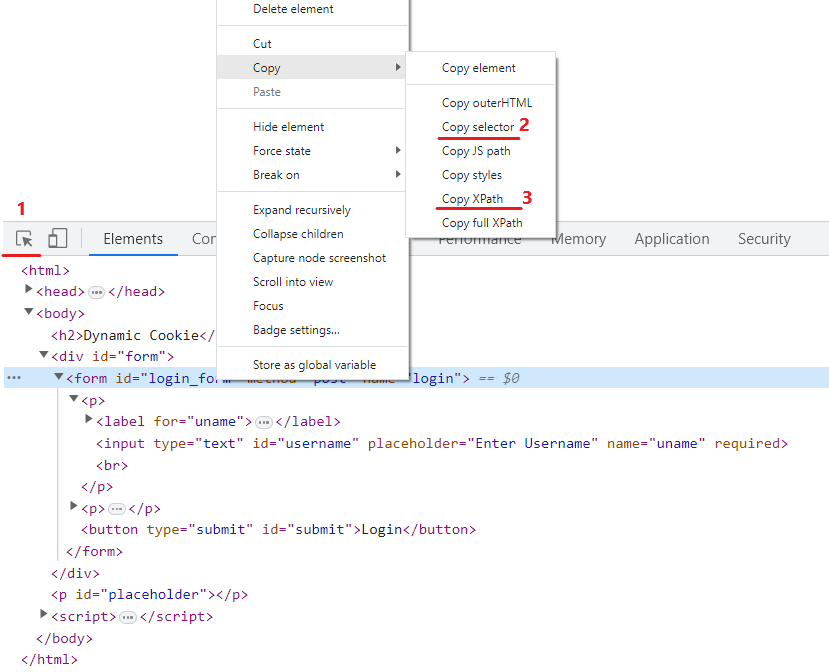
- Lokalisiert ein Element im DOM.
- Kopiert den CSS Selektor eines Elements.
- Kopiert den XPATH Selektor eines Elements.
Sind die Selektoren notiert, können diese im Konsolen Tab der Developer Konsole wie folgt getestet werden:

Wenn alle Elemente der Login Seite gefunden wurden, kann damit begonnen werden, den Ablauf der Anmeldung in der Konsole nachzustellen:
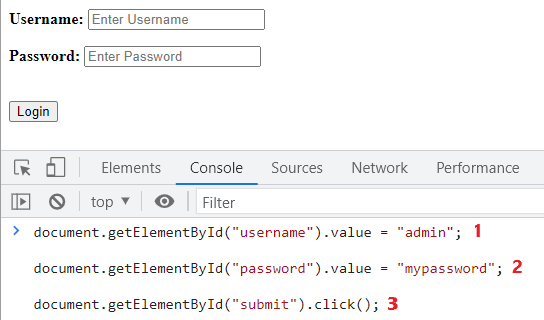
- Geben Sie Ihren Benutzername ein
- Geben Sie Ihr Passwort ein
- Drücken Sie auf „Login“
Wenn die Anmeldung über die Developer Konsole erfolgreich war, können die drei Befehle mit dem zugehörigen Script Trigger Selector als eigenständiges Credential-Skript im Management Center angelegt werden.
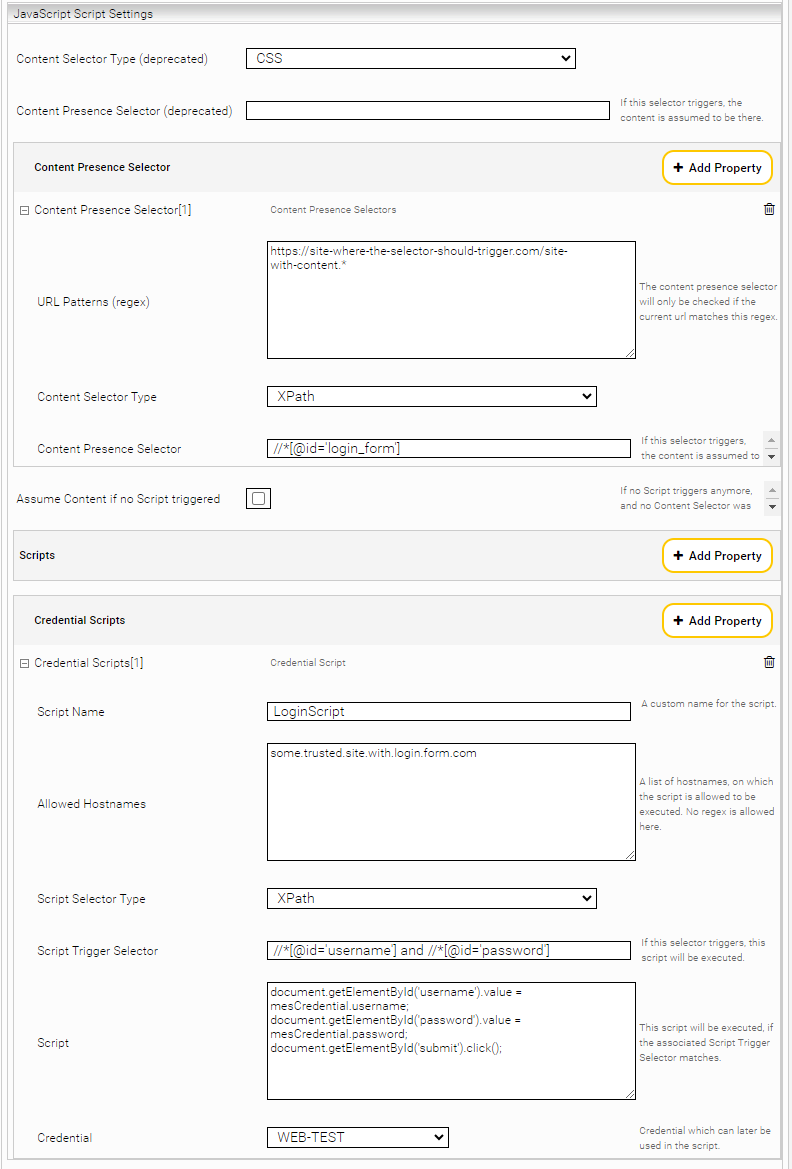
Inhaltsseiten-/Weiterleitungen (Weitergeleitete Seiten)
Die Inhaltsseiten enthalten die gewünschten, zu indizierenden Inhalte. Sie können mehrere Content Presence Selectors definieren, um diese Inhaltsseiten zu identifizieren. Es ist wichtig, dass alle Content Presence Selectors relativ streng konfiguriert werden. Der Grund dafür ist, dass die Content Presence Selectors nur auf die gewünschten URLs angewendet werden sollen. Dies wird in der Einstellung URL Patterns definiert. Außerdem sollte der CSS- oder XPath-Wert des Content Presence Selectors präzise definiert sein, damit auch auf verzögertes Laden der gewünschten Inhalte gewartet wird.
Für diesen Schritt ist ebenfalls wichtig, dass ALLE Seiten geprüft werden (nicht nur Start-/ Login-Seite).
In manchen Fällen kann es vorkommen, dass auch für die Inhaltsseiten spezielle Benutzerinteraktionen ausgeführt werden müssen, um den endgültigen Inhalt zu sehen. Hierfür werden ebenfalls Skripte konfiguriert, wobei die Vorgangsweise dieselbe wie beim Login-Skript ist.
- Selektoren identifizieren (Trigger-Selektor & Selektor des Elements mit dem interagiert wird)
- Selektoren testen
- Benutzerinteraktion in der Development Konsole nachahmen
- Script in die Konfiguration übernehmen und die Indizierung testen
Weitergeleitete Seiten verhalten sich wie normale Inhaltsseiten, und werden genau wie diese behandelt.
Wenn Benutzerinteraktionen nötig sind muss ein Skript konfiguriert werden, ansonsten wird das Standardverhalten des JavaScript Prozess ausgeführt.
Wenn auf Hosts verlinkt wird, welche nicht der konfigurierten „Crawling Root“ Hosts entsprechen, müssen diese zusätzlich als Additional Network Resources Hosts angegeben werden.^
Hinweise zu nicht unterstützte Autorisierungsformen
Aktuell werden folgende Autorisierungsformen noch nicht unterstützt:
- Klassische Pop-ups mit Login-Formularen, da das Pop-up-Fenster nicht vom Hauptdokument aus zugänglich ist. Oft bieten Identity Provider (IDPs) Möglichkeiten, einen Login-Prozess ohne Pop-up durchzuführen. Dies sollte in solchen Fällen bevorzugt werden.
- Authentifizierung über „HTTP Request Header“ wird nur eingeschränkt unterstützt, solange keine Redirects oder XHR-Requests mit diesen Headern erfolgen.
Webseiten mit Akkordeons
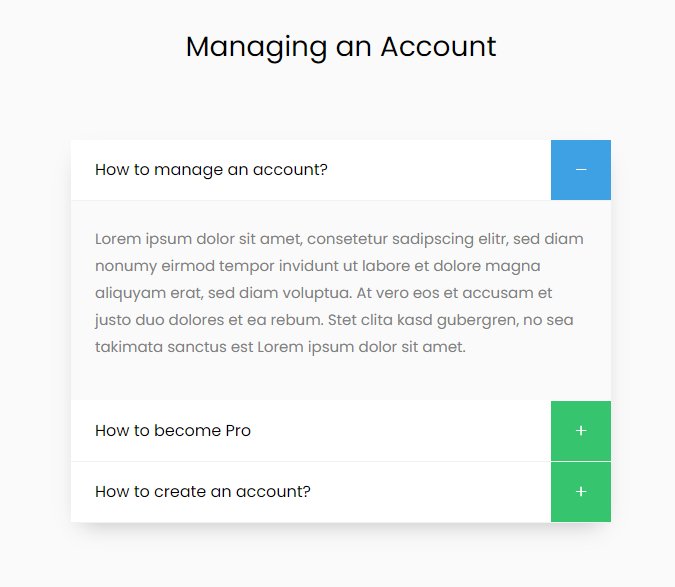 In diesem Beispiel wird erklärt, welche Schritte für die Einrichtung des Mindbreeze Web Konnektors zum Crawlen von Webseiten mit Akkordeons notwendig sind.
In diesem Beispiel wird erklärt, welche Schritte für die Einrichtung des Mindbreeze Web Konnektors zum Crawlen von Webseiten mit Akkordeons notwendig sind.
Vorgehensweise
Wenn die Webseite den Inhalt des Akkordeons in den DOM lädt, müssen keine weiteren Schritte zum Aufklappen dieser getätigt werden.
Ansonsten muss gecheckt werden, ob es sich bei der Webseite um eine Single Page Applikation handelt, da diese aktuell nicht unterstützt werden. (Einschränkungen der "Enable JavaScript" Option). Diese Einschränkung kann jedoch in gewissen Fällen umgangen werden.
Grundsätzlich ist es zum Laden des Inhalts wichtig, dass es bei Akkordeons die Möglichkeiten gibt:
- Alle Akkordeon-Elemente auszuklappen
- Jeweils nur ein Akkordeon-Element auszuklappen
Für beide Arten sind Benutzerinteraktionen notwendig und das Ziel ist es, den gesamten Inhalt in den DOM zu laden.
Ausklappen aller Akkordeon-Elemente
Wenn alle Elemente des Akkordeons gleichzeitig ausklappbar sind reicht ein Skript, das auf die jeweiligen Schaltflächen klicken um den Inhalt zu laden.
Wenn nicht alle Elemente gleichzeitig ausklappbar sind, wird zuerst ein Skript benötig um diesen Mechanismus zu deaktivieren, da ansonsten nicht der ganze Inhalt vorhanden ist.
Dieser Mechanismus kann mittels JavaScript auf der Webseite implementiert sein, jedoch auch durch die Eigenschaften des verwendeten Frameworks bestimmt werden.
Bei Unklarheiten dahingehend sollten die Webentwickler der Webseite kontaktiert werden, um die Möglichkeiten zur Deaktivierung dieses Mechanismus abzuklären.
Wenn der Mechanismus deaktiviert ist kann wie zuvor ein Script die einzelnen Akkordeonelemente aufklappen.
Unendliches Scrollen
In diesem Beispiel wird erklärt, welche Schritte für die Einrichtung des Mindbreeze Web Konnektors zum Crawlen von Webseiten, die unendliches Scrollen unterstützen, notwendig sind.
Vorgehensweise
Wenn die Webseite den kompletten Inhalt in den DOM lädt, müssen keine weiteren Schritte zum Scrollen getätigt werden.
Wenn dies nicht der Fall muss mit einem Skript bis zum Ende der Seite gescrollt werden, sodass der ganze Inhalt im DOM verfügbar ist.
Die Schwierigkeit dabei ist es zu erkennen, wann man ganz unten angekommen ist, da dies bei Webseiten nicht einheitlich ist.
„Keine weiteren Ergebnisse“ Benachrichtigung
Bei Webseiten die am Ende der Liste eine „Keine weiteren Ergebnisse“ Benachrichtigung, die nicht immer im DOM existiert, einblenden reichen ein „Content Presence Selector“ der diese Benachrichtigung adressiert, sowie ein Skript das nur hinunter scrollt aus.
Wenn die Benachrichtigung immer im DOM vorhanden ist, muss wie bei Ladeanimationen versucht werden das Ende des Dokuments zu ermitteln.
Ladeanimation für weitere Ergebnisse
Wenn keine Benachrichtigung am Ende der Liste vorhanden ist, muss mittels eines Scripts und der Einstellung „Assume Content if no Script triggered“ herausgefunden werden wann das Ende dieser erreicht wurde.
Dazu können die Ladeanimation der Liste, sowie mehrere Höhenparameter verwendet werden.
Um die Iteration des Skripts zu beenden muss beim Erreichen des Endes der Liste der verwendete „Script Trigger Selector“ im HTML geändert werden.
Beispiele
„Keine weiteren Ergebnisse“ Benachrichtigung
Bei der zu indizierende Webseite muss bis ganz unten gescrollt werden um alle Elemente anzeigen zu können. Solange die Liste mit den Elementen gefunden wird soll versucht werden hinunter zu scrollen. Wenn das Ende dieser Liste erreicht wurde, wird eine Nachricht mit „Keine weiteren Ergebnisse“ angezeigt.
- Content Presence Selector (CSS): #no-more-results
- Script Trigger Selector (CSS): #result-tree
- Script: window.scrollTo(0, document.body.scrollHeight)
Das Skript wird so lange ausgeführt bis der Content Presence Selector triggert (das Ende erreicht wurde).
Ladeanimation für weitere Ergebnisse
Bei der zu indizierende Webseite muss bis ganz unten gescrollt werden um alle Elemente anzeigen zu können. Solange die Liste mit den Elementen gefunden wird soll versucht werden hinunter zu scrollen. Wenn weitere Ergebnisse verfügbar sind wird dies mit einer Ladeanimation angezeigt. Wenn das Ende dieser Liste erreicht wurde, wird keine Nachricht angezeigt.
- Assume Content if no Script triggered: true
- Script Trigger Selector (CSS): .element-list
- Script:
if (window.innerHeight + window.pageYOffset == document.body.offsetHeight &&
document.getElementsByClassName('element-list').length == 0)
{
document.getElementsByClassName('element-list')[0].className =
'element-list-done';
} else {
window.scrollTo(0, document.body.scrollHeight);
}
Der Abschnitt zum Überprüfen ob man bereits fertig hinunter zu scrollen, erfolgt hier durch die Bedingungen
window.innerHeight + window.pageYOffset == document.body.offsetHeight
document.getElementsByClassName('element-list').length == 0
Der erste Teil checkt ob das Ende des Dokuments erreicht wurde. Da dieses Script jedoch sehr oft ausgeführt wird kann es vorkommen, dass das Ende durch den Ladebalken, der signalisiert, dass noch mehr Objekte geladen werden, erreicht wird. Um dies zu vermeiden wird auch der Ladebalken auf sein Vorhandensein geprüft.
Wenn beide Bedingungen erfüllt sind, wird der Tag der als Content Trigger Selector dient, geändert damit das Script nicht weiter triggert. Ansonsten wird weiter nach unten gescrollt.
Eingabe wird nicht erkannt
Vorgehensweise
Wenn mittels JavaScript Text eingefügt wird (Eingabe des Benutzername) kann es vorkommen, dass beim anschließenden Klick auf Weiter/Enter/… dieser nicht erkannt wird bzw. der Text „geben Sie eine gültige Email ein“ auftaucht.
Dies ist zum Beispiel beim Login auf „login.microsoftonline.com“ der Fall und geschieht, weil hinter dem Feld eine Interaktionsvalidierung steckt die bei einer Eingabe mit JavaScript nicht getriggert wird, und das Feld deshalb als leer erkannt wird.
Um dieses Verhalten auf „login.microsoftonline.com“ zu umgehen, muss ein Event getriggert werden um das Benutzerverhalten zu simulieren.
Beispiel
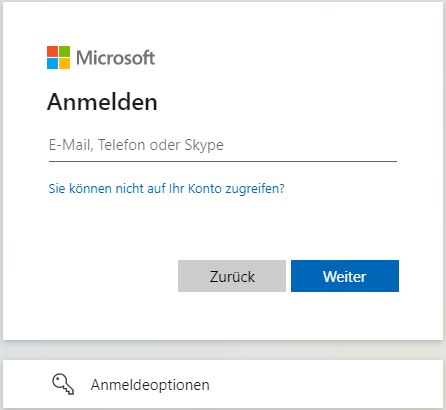
const benutzername = document.getElementById('benutzername');
const weiter = document.getElementById('weiter');
const event = new Event('change');
benutzername.value = mesCredential.username;
benutzername.dispatchEvent(event);
weiter.click();
JavaScript-Meldung im Inhalt
Wenn Sie in einem indizierten Dokument auf Inhalte stoßen, die Sie auffordern, JavaScript zu aktivieren, wurde der „Content Presence Selector“ möglicherweise nicht aktiviert oder so eingestellt, dass er bereits auslöst, bevor die Webseite vollständig geladen wurde.
Dies führt dazu, dass der Content zu früh indiziert wird und die Nachricht nicht aus dem DOM gelöscht wird. Definieren Sie bitte einen präziseren „Content Presence Selector“, der den zu indizierenden Inhalt vollkommen inkludiert.
Troubleshooting
Generell
Wenn zu wenige, zu viele, unvollständige oder keine Dokumente indiziert werden, prüfen Sie die folgenden Punkte:
- Konfiguration auf Korrektheit überprüfen
- Selektoren
- Scripts
- Reduzieren Sie die Einstellung „Number of Crawler Threads“ auf 1.
- Wenn Sie mit einer Sitemap arbeiten, reduzieren Sie die Anzahl der URLs auf 1.
- Prüfen Sie mittels CURL, ob ein HEAD Request zur Webseite gemacht werden kann.
- Wenn dies nicht möglich ist (Weil z.b. die Methode nicht erlaubt ist, oder der HEAD Request Authorisierung benötigt), aktivieren Sie die Einstellung „Skip Head Request“
- curl -I -v https://....
- Webseite auf Reaktionszeit überprüfen, Timeouts anpassen
- Logs auf Fehler überprüfen
- siehe 5.2 Logs
- Überprüfen in app.telemetry
- Crawler Service und Index Service checken
- Überprüfen der Screenshots
- siehe 5.2 Logs
- Überprüfen der System Zeit
- Es muss sichergestellt werden, dass die System Zeit auf dem Inspire System mit der des aktuellen Systems übereinstimmt. Dies kann im Management Center unter
System – System Time eingestellt werden.
- Es muss sichergestellt werden, dass die System Zeit auf dem Inspire System mit der des aktuellen Systems übereinstimmt. Dies kann im Management Center unter
Logs
In diesem Abschnitt werden die wichtigsten Logs, die für die Analyse des Web Konnektors im JavaScript Modus benötigt werden, aufgeführt.
Alle Log-Pfade werden ausgehend von folgendem Pfad angegeben: /data/logs/crawler-log/current
Zuerst sollten die allgemeinen Logs des Web Konnektor Logs überprüft werden. Die wichtigsten dafür sind:
- log-mescrawler_launchedservice.log
bietet eine generelle Übersicht zum Web Konnektor Prozess. - /job/logs/crawl.log
bietet eine Übersicht über die gecrawlten Seiten und deren Status-Code und andere Metadaten.
Wenn aus diesen Logs keine nützlichen Informationen gewonnen werden können, müssen die Logs des JavaScript-Prozesses überprüft werden.
Um alle diese Log Dateien zu erhalten, muss im Management Center unter Advanced Settings die Einstellung „Enable Verbose Logging“ aktiviert werden.
Alle folgenden Logs werden ab folgendem Pfad angegeben:
/data/logs/crawler-log/current/log-webdriver-webdriver/current
Die allgemeinen Logs zum JavaScript Prozess sind:
- log-webdriver.log
bietet eine generelle Übersicht zum JS Prozess. - chromedriver-network.csv
bietet eine Übersicht über alle Webseiten die während des JS Prozesses aufgerufen werden, sowie deren Status Code und andere Metadaten. - chromedriver-javascript-process.csv
bietet eine Übersicht zum JS Prozess im CSV-Format mit Referenzen zu Screenshots
Die erweiterten Logs zum JavaScript Prozess sind:
- /chromedriver-logs/<driver-port>/driver-actions.log
bietet eine Übersicht über alle Aktionen, die der Crawler ausführt an. In diesem Log werden, wenn konfiguriert, Login Scripts mit Benutzername und Passwort angezeigt. - /chromedriver-logs/<driver-port>/network-performance.log
bietet eine Übersicht über ALLE Netzwerk Aktionen, die der Prozess ausführt an.
Vergleichbar mit der Netzwerkübersicht in den DevTools (F12). - /chromedriver-logs/<driver-port>/page-lifecycle.log
bietet eine generelle Übersicht über den Zustand der aktuellen Webseite an. - /chromedriver-logs/<driver-port>/cdp-logs.log
bietet eine Übersicht über Fehler und Warnungen im JS Prozess an. In diesem Log werden, wenn konfiguriert, Login Scripts mit Benutzername und Passwort angezeigt. - /chromedriver-logs/<driver-port>/unhandled-events.log
listet alle "Chrome Driver Events" auf, die nicht speziell vom Webdriver verarbeitet wurden. - /chromedriver-browser-snapshots/<driver-port>/*
hier werden alle Screenshots gespeichert, die während dem JS Prozess erstellt werden.
Diese können durch die Datei chromedriver-javascript-process.csv zugeordnet werden.
In den hier gespeicherten Screenshots werden, wenn konfiguriert, Login Scripts mit Benutzername und Passwort angezeigt.
Timeouts
Wenn Webseiten nicht indiziert werden, können häufig Timeouts der Grund dafür sein.
Dazu gibt es die zwei Einstellungen „Page Load Timeout“ und „Network Timeout“.
Sollten Sie eine der folgenden Fehlermeldungen sehen:
TimeoutException: Waiting for the pages readyState took too long.
TimeoutException: Couldn't find content in time. …
befolgen Sie diese Schritte:
- Rufen Sie die Webseite im Browser auf, messen Sie die Ladezeit.
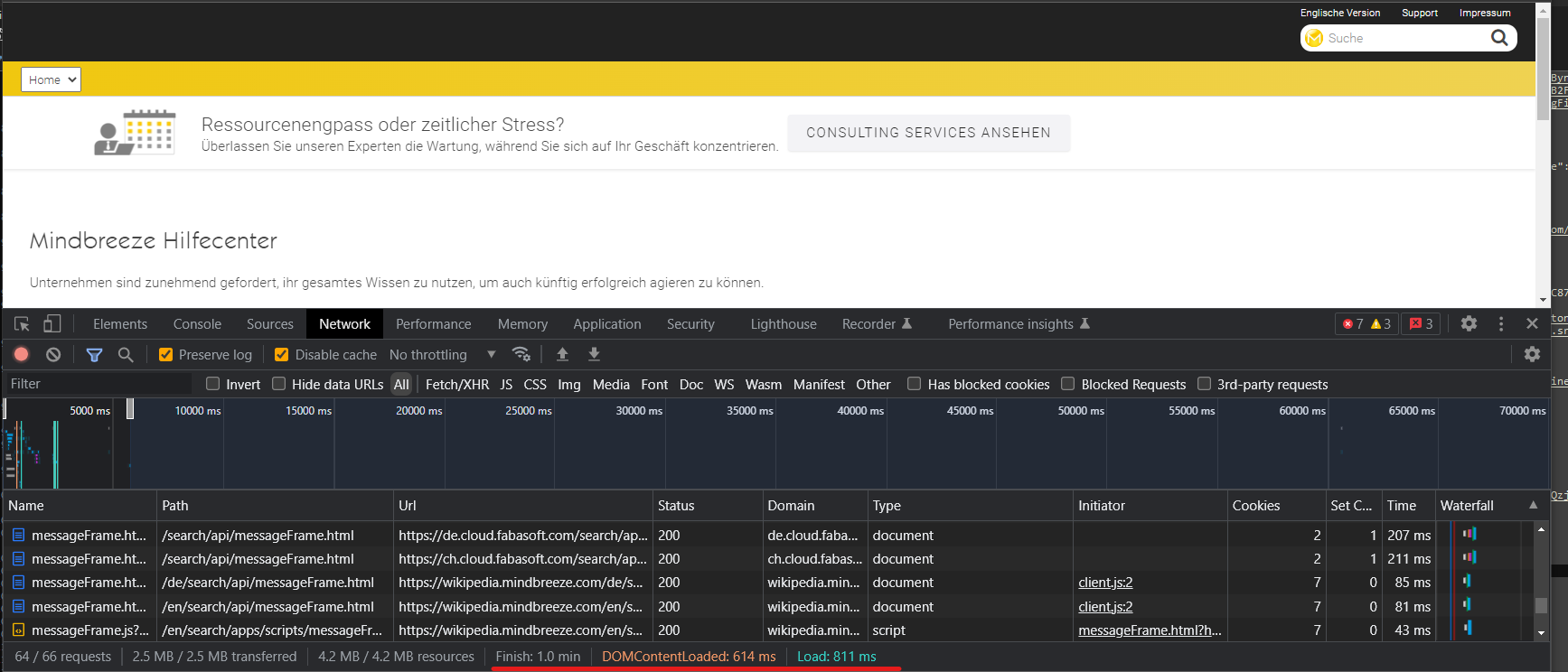
- Passen Sie die zwei Timeout-Einstellung nach diesem Ergebnis an.
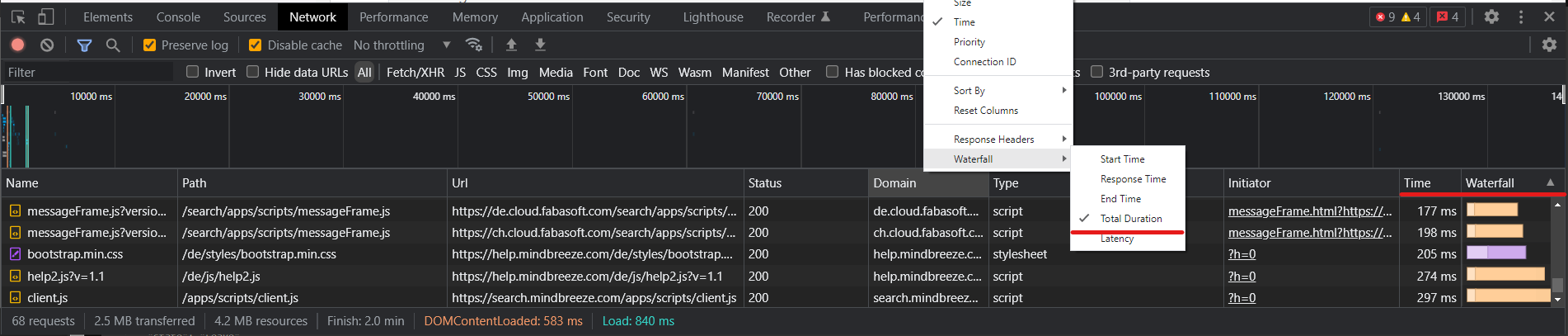
- Sollten die Timeout-Probleme immer noch auftauchen, vergleichen Sie die Ausgabe der DevTool-Spalten „Time“ und „Waterfall“ mit den Ergebnissen, die Sie in der AppTelemetry finden werden.
- Achten Sie darauf, die Spalte „Waterfall“ auf „Total Duration“ umzustellen.
In AppTelemetry wechseln Sie zum LogPool „Network Requests“ und wählen Sie „View Telemetry Data“.
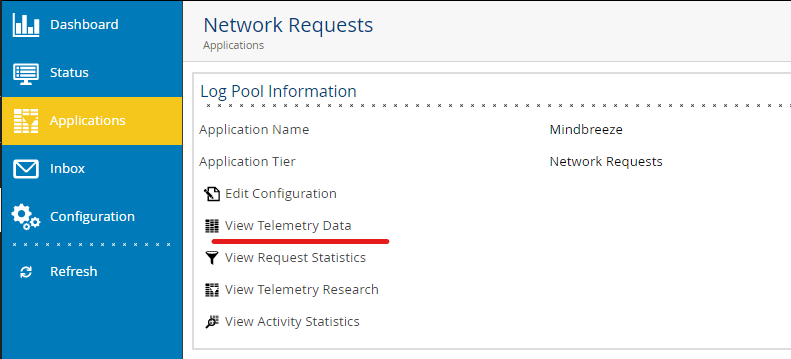
Um eine bessere Übersicht über die Requests zu bekommen, filtern Sie nach dem Service „Network Requests – webdriver-webdriver“ und der aktuellen Thread ID, um eine Übersicht zum gesamten Request zu bekommen.
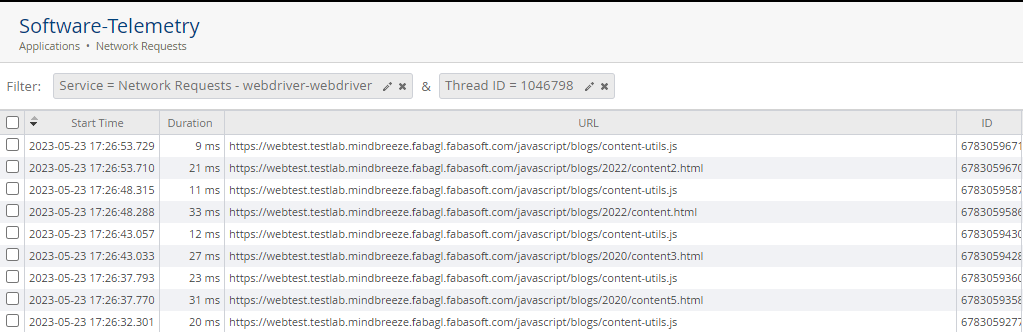
Vergleichen Sie nun anhand der URLs, ob die Zeiten ungefähr im selben Bereich liegen. Beachten Sie jedoch, dass der Crawler mögliche Benutzerinteraktionen schneller erledigt und diese Requests nicht vergleichbar sind.
Wenn die Zeiten sehr stark abweichen, kann es sich um ein Netzwerkproblem zwischen der Mindbreeze Appliance und dem Ziel-Server handeln.
Sollten Sie solche Verbindungsprobleme feststellen, kontaktieren Sie die zuständigen Personen in Ihrer Organisation.
Robots.txt
In manchen Fällen verhindert eine robots.txt-Datei der Webseite das korrekte crawlen.
Dies ist im crawl.log (siehe 5.2 Logs) ersichtlich, wenn keine anderen Seiten neben der robots.txt auftauchen.
![]()
Dieses Verhalten kann durch die Einstellung „Exclude JavaScript URL (regex)“ umgangen werden. (.*robots.txt)
Selektoren
Wenn „Content Presence Selector“ oder „Script Trigger Selector“ bei Inhalten nicht wie erwartet ausgeführt werden, sollte das Log „/current/log-webdriver-webdriver/current/chromedriver-logs/driver-actions.log” überprüft werden.
Dort suchen Sie nach: „isElementPresent“. An dieser Stelle werden die Selektoren verarbeitet, und im Falle von Syntax Fehlern würden diese im Leave-Event angezeigt werden. Im folgenden Screenshot sehen Sie einen Log-Eintrag ohne Syntaxfehler.

Wichtig dabei ist zu beachten, dass Selektoren nur mit einfachen Anführungszeichen angegeben werden sollen. Sollten doppelte Anführungszeichen verwendet werden, müssen diese vorher mit „\“ escaped werden.
Content Presence Selector immer vorhanden
In manchen Fällen kann es vorkommen, dass keine Skripts ausgeführt werden und falscher Inhalt indiziert wird.
Dies passiert, wenn der „Content Presence Selector“ bereits im DOM verfügbar ist, aber noch nicht angezeigt wird. Das kann dazu führen, dass die Ausführung des Skrips nicht stattfindet und der Inhalt sofort indiziert wird.
Ein Beispiel dafür wäre ein Pop-Up auf einer Webseite (Werbebanner), das weggeklickt werden soll. Der zu indexierende Inhalt inklusive „Content Presence Selector“ ist jedoch bereits im DOM geladen, weshalb das Skript nie ausgeführt wird.
In diesem Fall muss der „Content Presence Selector“ präziser gewählt werden und entsprechend für das zu entfernende Element angepasst werden.
Content Presence Selector nicht definierbar
Wenn ein „Content Presence Selector“ nicht definiert werden kann (ändernde IDs, Inhalt immer im DOM, …) kann auch mittels Scripts in bestimmten Fällen ein HTML Element definiert werden, das dann wiederum als „Content Presence Selector“ fungiert.
Dies ist jedoch nur zu verwenden wenn keine andere Möglichkeit besteht, einen Selektor zu definieren.
if (!document.getElementById('banner') {
document.body.appendChild(document.createElement('exit'));
}
Beispiele
Gültige Beispiele:
XPath:
//*[@id='content']
//*[@id=\"content\"]
CSS:
a[href^= 'https']
a[href^=\"https\"]
Ungültige Beispiele:
XPath:
//*[@id="content"]
CSS:
a[href^="https"]
Sitemaps
Wenn Sitemaps von einem Filesystem importiert werden und nicht mit einer URL, dann muss der root host explizit in den „Additional Network Resources Hosts“ angegeben werden da dieser nicht durch die URL ermittelt werden kann.
Fehlermeldungen beim Crawlen
net::ERR_ABORTED
Manchmal wird für Dokumente im chromedriver-network.csv die “Status Code Description” “net:ERR_ABORTED” angezeigt.
Wenn dies der Fall ist, muss speziell auf die Spalten “Website URL” und „Network Resource URL“ geschaut werden, welche die angeforderte URL und die aktuelle URL anzeigen.
Diese sind meist unterschiedlich da die aktuell URL die angeforderte Ressource (jpg, js, svg, redirected url, …) repräsentieren.
Nach diesen URLs kann nun im cdp-logs.csv Dokument gesucht werden um eine detaillierte Beschreibung des Fehlers zu bekommen.
net::ERR_BLOCKED_BY_CLIENT.Inspector
Wenn dieser Fehler auftritt, wurden spezifische Hosts nicht für den Crawler freigeschalten. Dies passiert mit der Einstellung „Additional Network Resources Hosts“.
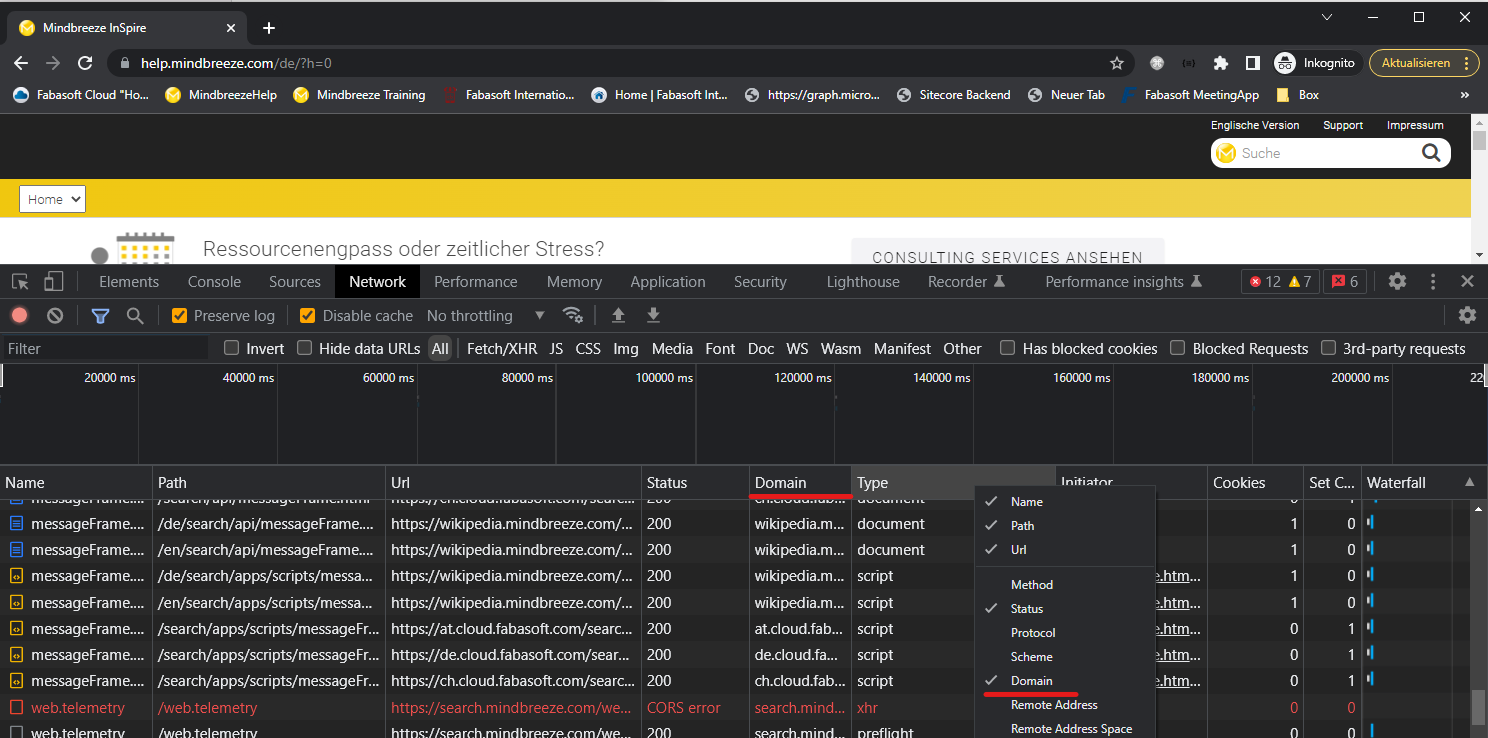
Um alle benötigten Hostnames herauszufinden, können die Developer Tools (F12) von Chrome verwendet werden um nach Domänen zu filtern.
Um ein korrektes Verhalten des Crawlers sicherzustellen, müssen ALLE Hostnames hinzugefügt werden.
- Öffnen Sie einen neuen inkognito Tab und die Developer Tools mit F12
- Navigieren Sie zur gewünschten Webseite und anschließend zum Reiter „Network“
- Wenn die Registerkarte „Domain“ noch nicht vorhanden ist, fügen Sie dise zu den vorhandenen Optionen hinzu, indem Sie mit der rechten Maustaste auf die Registerkarte klicken.