
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Release Notes für Mindbreeze InSpire
Version 21.3
Innovationen und neue Features
Mindbreeze zeigt kontextspezifische Ergebnisse auch wenn nicht alle Suchbegriffe übereinstimmen
Um das Sucherlebnis noch weiter zu optimieren, haben wir im Rahmen der neuen Release ein Feature entwickelt, dass das Auffinden von Inhalten optimiert. Es ermöglicht, dass Mindbreeze InSpire nun auch Inhalte als Ergebnisse zur Verfügung stellt, die nicht jeden einzelnen Suchbegriff beinhalten, jedoch kontextbezogen ebenso relevant sind. Damit das transparent für den Nutzer geschieht, ist direkt beim Suchresultat ein entsprechender Hinweis ersichtlich, der verdeutlicht welche Begriffe nicht im Suchresultat vorkommen.

Standardmäßig findet Mindbreeze InSpire Inhalte, die mindestens zwei Drittel der Suchbegriffe enthalten. Konkret bedeutet dies: Enthält eine Suchanfrage beispielsweise fünf Suchbegriffe, kann ein Begriff im Resultat fehlen, damit das Ergebnis aufgrund der kontextuellen Relevanz dennoch angezeigt wird. Der oben gezeigte Screenshot zeigt ein Beispiel, bei dem für die Suchanfrage „Artificial Intelligence Human Interaction Article“, ein Dokument gefunden wird, welches den Begriff „Article“ nicht enthält.
Aufgrund der enormen Vorteile ist dieses Feature standardmäßig aktiviert. Es besteht jedoch die Möglichkeit es zu parametrisieren oder bei Bedarf zu deaktivieren.
In diesem Zusammenhang wurden auch Optimierungen der Query Expression Transformation Pipeline und Relevanz vorgenommen. Das Erweitern der Suchbegriffe aus Synonymkatalogen und das Einführen von Wortaliase durch morphologische Varianten, wird nun so durchgeführt, dass die Repräsentation der originalen Sucheingabe vollständig erhalten bleibt. Auf diese Weise kann eine höhere Trefferqualität gewährleistet werden.
In Bezug auf die Relevanz erfolgt nun zusätzlich die Gewichtung der einzelnen Suchbegriffe abhängig von der Reihenfolge der Eingabe. Um die Relevanz der Ergebnisse zu steigern wurde darüber hinaus die Berechnung der Nähe der eingegebenen Begriffe im Trefferkontext weiter optimiert. Dies kann ebenfalls parametrisiert oder ganz deaktiviert werden.
Arbeitsplatzintegration in Salesforce
Im Rahmen unserer 21.3 Release haben wir die innovative Möglichkeit geschaffen, Mindbreeze InSpire Insight Apps nahtlos in Ihre Salesforce-Anwendung zu integrieren. Nutzern steht damit der volle Funktions- sowie Leistungsumfang von Mindbreeze InSpire direkt in ihrer gewohnten Arbeitsumgebung zur Verfügung.
Das bedeutet unter anderem, dass Anwender für eine Suchanfrage die Anwendung nicht verlassen müssen. Kommt es zu einer Rechercheabfrage, extrahiert Mindbreeze InSpire automatisch sowohl Salesforce-spezifische Dokumente als auch Inhalte aus externen angebunden Datenquellen.
So schafft eine Arbeitsplatzintegration von Mindbreeze InSpire in Salesforce die ideale Basis für eine umfassende Interaktion mit der Anwendung. Aus Anwendersicht ergeben sich dadurch zahlreiche Möglichkeiten, die Funktionalitäten von Mindbreeze InSpire noch tiefgehender zu nutzen.
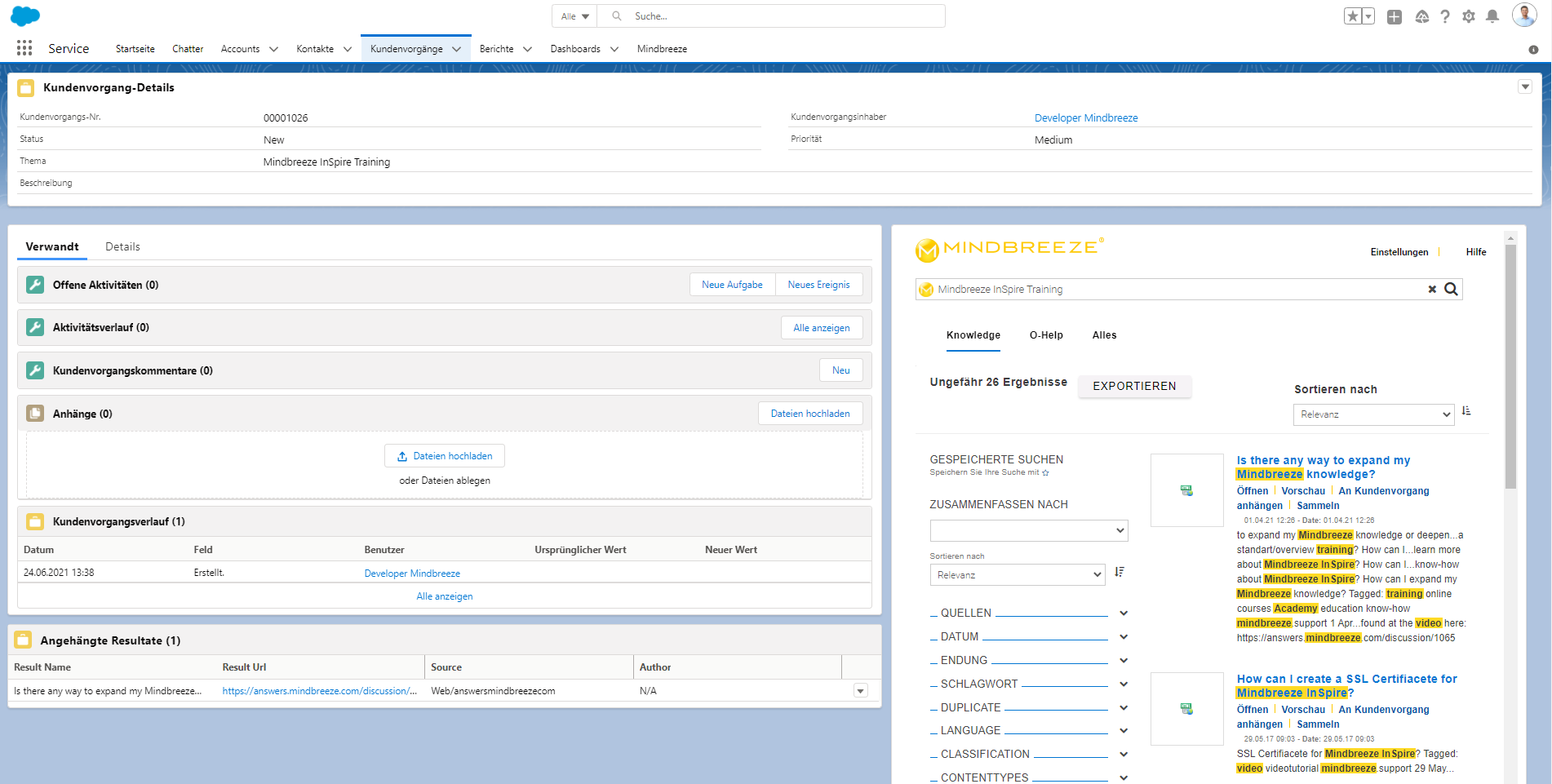
Dies könnte zum Beispiel das automatisierte Anstoßen einer Suchabfrage beim Aufrufen eines konkreten Falls („Kundenvorgang“) sein. Wird dies umgesetzt, löst die Navigation zu einem in Salesforce abgelegten Fall, automatisiert eine Suche aus („Zero Term Search“). Anwender werden auf diese Weise mit zusätzlichen, kontextrelevanten Inhalten versorgt.
Ein weiteres Beispiel in diesem Zusammenhang besteht in der Möglichkeit Suchergebnisse an einen Fall anzuhängen. Möchte ein Anwender ein bestimmtes Dokument aus den automatisiert angestoßenen Suchergebnissen zu dem spezifischen Fall abspeichern, wäre dies durch den einfachen Klick auf "An Kundenvorgang anhängen“ möglich.
Optimierung der In-Memory Berechnungen für Insight Apps und Analytics
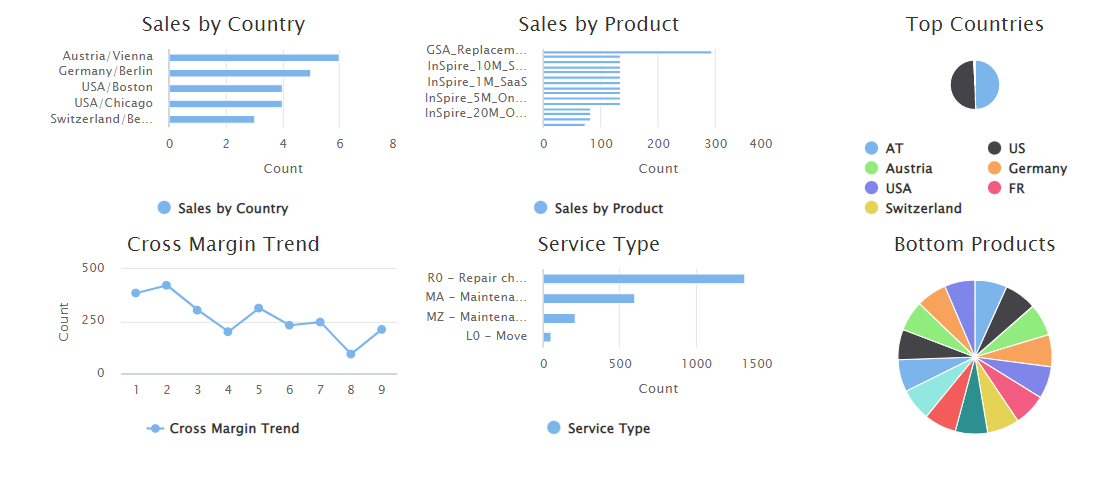
Mit diesem Feature waren wir in der Lage eine deutliche Leistungsoptimierung umzusetzen. Dank der Verwendung von In-Memory Berechnungen, ist Mindbreeze InSpire in der Lage, Daten für Insight App Darstellungen wie etwa Filter und Charts weitaus schneller zu verarbeiten. Die dafür notwendigen dimensionalen Metadaten, welche dynamisch pro Dokument definiert sind, werden nun signifikant schneller prozessiert.
Auf diese Weise lassen sich beispielsweise komplexe Dashboards (wie beispielsweise im folgenden Screenshot) um vieles schneller darstellen.
Erweiterte Konnektoren
Salesforce Konnektor unterstützt die Enterprise Collaboration Plattform „Salesforce Chatter“
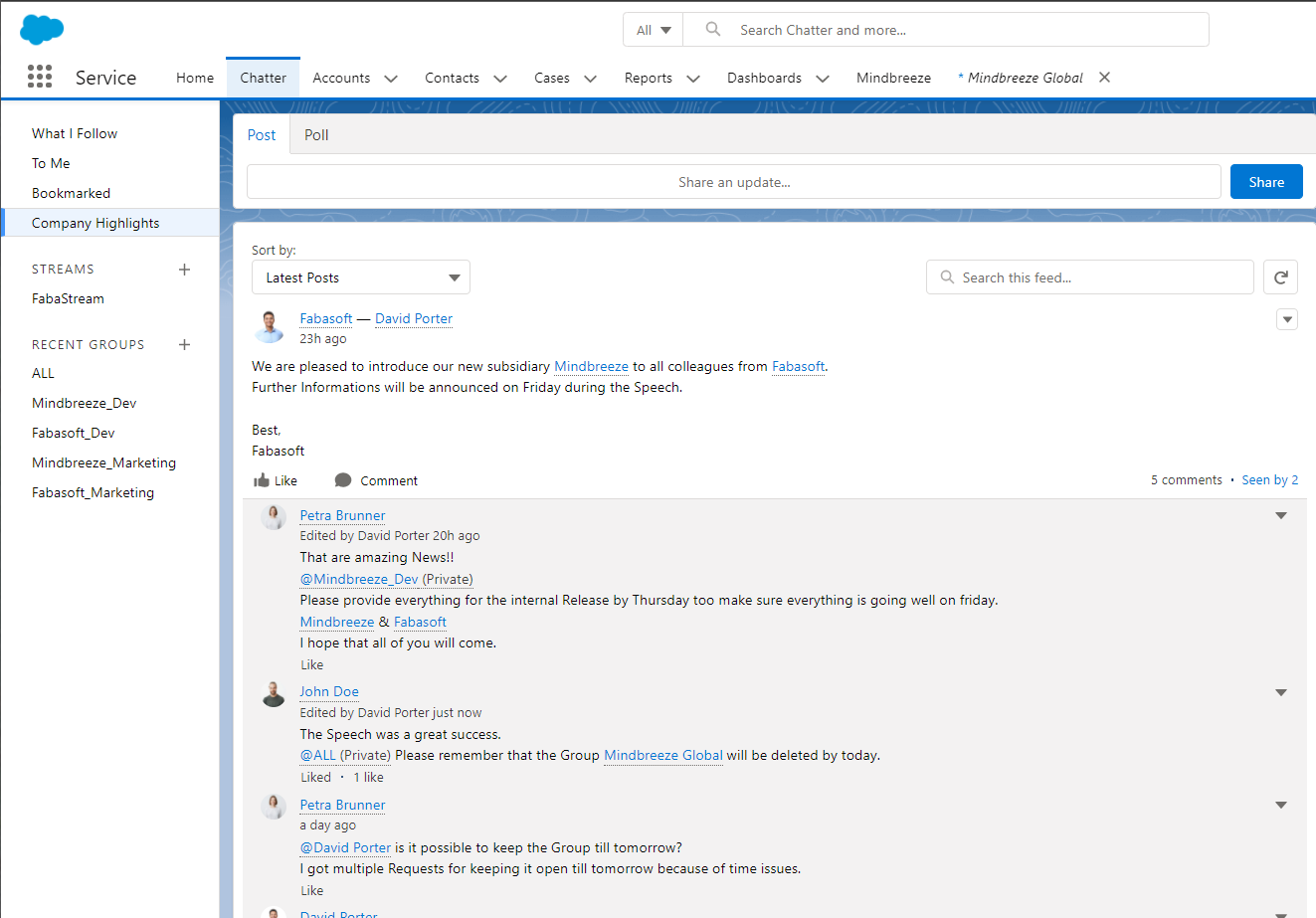
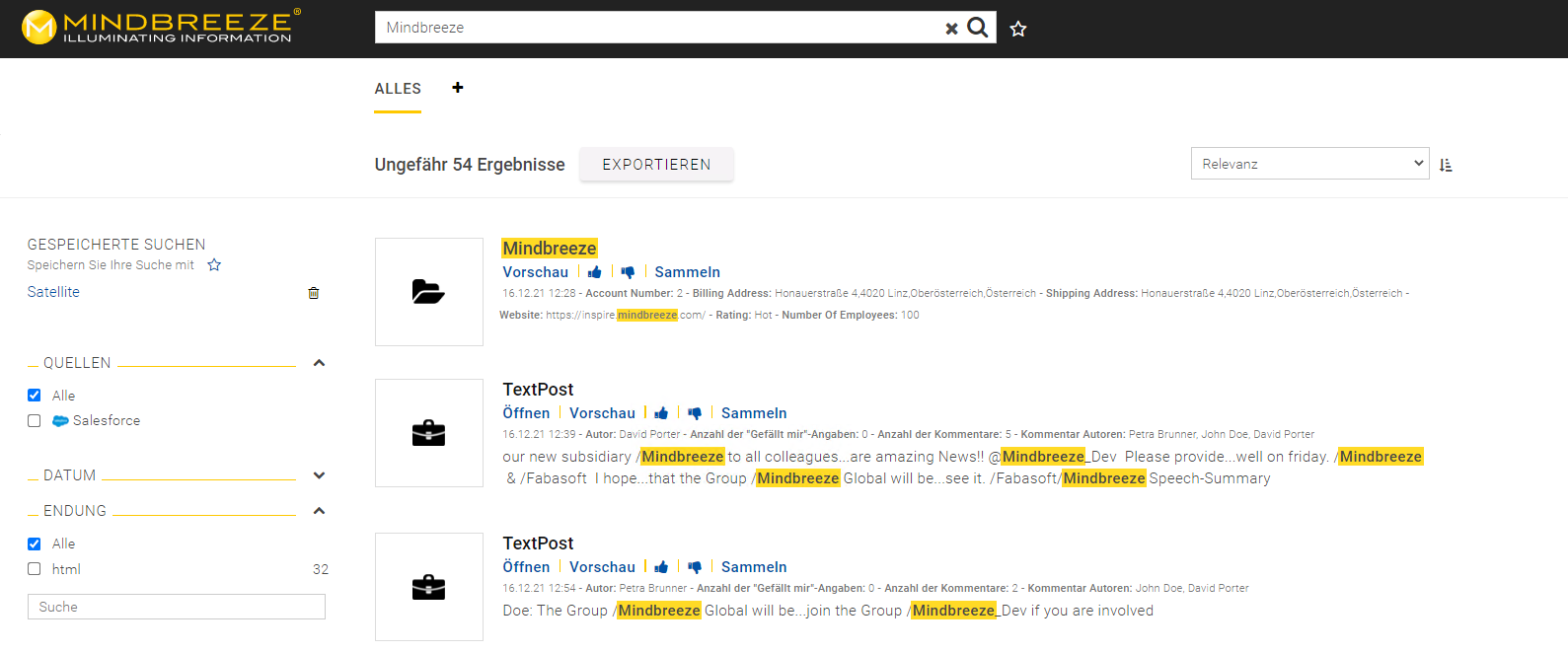
Damit Sie Salesforce noch umfangreicher mit Mindbreeze InSpire verknüpfen können, bieten wir nun auch die Möglichkeit Informationen aus dem Sozialen Netzwerk „Salesforce Chatter“ einzubeziehen.
Dank der Erweiterung des Salesforce Konnektors lassen sich nun auch Beiträge, Nachrichten und Posts, sogenannte Feed Items der Corporate Social Media Plattform indizieren. Dies verschafft Anwendern einen noch umfassenderen und tieferen Einblick auf die vorhandenen Informationen über alle eingesetzten Salesforce-Systeme hinweg.
GitHub Wiki Pages
Die neue Version des GitHub Konnektors unterstützt ab sofort auch das Crawlen über Wiki Pages.
Auf diese Weise lassen sich nun ebenso Dokumentationen des Source Codes unkompliziert und effizient durchsuchen.
Zusätzlich haben wir die Möglichkeit geschaffen, wenn gewünscht die Indizierung der Issues und Pull Requests zu deaktivieren, wodurch sich unter anderem die Crawling-Zeiten auf ein Minimum verringern lassen.
Inkrementelle Verarbeitung von Dokumenten Google Drive
Unser Google Drive Konnektor unterstützt ab sofort die effiziente inkrementelle Verarbeitung von Dokumenten. Dies dient vor allem der Optimierung der Crawling-Zeiten und gewährleistet stets die Aktualität der verfügbaren Daten. Mindbreeze InSpire indiziert dabei nur geänderte, gelöschte sowie hinzugefügte Dateien, was besonders bei einer großen Menge von Dokumenten deutliche Vorteile bringt.
Microsoft SharePoint Online Managed Metadata
Eine Erweiterung des SharePoint Online Konnektors unterstützt nun auch das Durchsuchen von Managed Metadaten. Dabei handelt es sich um eine spezielle Form von Metadaten, die durch das Kategorisieren von Eigenschaften (z.B. der Begriff Abteilung) und speziellen Werten (Marketing, Sales, HR…) die Handhabung vereinfachen.
Falls Sie Managed Metadaten nutzen möchten, können Sie die entsprechende Option „Index Complex Metadata Types“ konfigurieren.
Technische Erweiterungen
Backend Service Authentifizierung über Service Accounts
Im Rahmen der technischen Erweiterungen unserer 21.3 Release, haben wir Anwendern die Möglichkeit gegeben, neben anderen Varianten auch JSON Web Token (JWT) mit Service Accounts für die Backend-Authentication zu verwenden. Diese steht Ihnen nun aufgrund ihrer zahlreichen Vorteile als Standardvariante zur Verfügung.
Neben einer höheren Sicherheit, durch Service Accounts, lässt sich diese Variante besser skalieren und ist robuster gegenüber Verbindungsproblemen zum IDP. Darüber hinaus bietet diese Variante den Vorteil, den IDP zu warten, ohne dabei die Suche zu beeinträchtigen.
Appliance Plattform Modernisierung
- Für Mindbreeze hat das Thema Sicherheit oberste Priorität. Damit unsere Lösung immer am neuesten Stand der Entwicklungen ist und Ihren hohen Ansprüchen genügt, aktualisieren wir Laufend das Betriebssystem unserer Appliances.
- Um auch in Zukunft die gewohnte Stabilität und den bestmöglichen Support bieten zu können, haben wir, im Rahmen dieser Release, das CentOS Atomic Host Betriebssystem durch die CoreOS Plattform ersetzt.
Neben rascheren Fehlerbehebungen, sorgt diese Veränderung auch für eine weitgehende Optimierung der Performance. Zudem ermöglicht der Wechsel des Betriebssystems In Place Updates für bestehende Appliances.
Ein Rollback zum Atomic Host bleibt weiterhin möglich und darüber hinaus stehen Ihnen sämtliche Atomic Host Vorteile weiterhin zur Verfügung.
Modernisierung der Insight Apps Plattform
Unsere 21.3 Release wird begleitet von einer umfangreichen Modernisierung der Insight Apps Plattform auf Entwicklerebene. Mit der Umstellung auf Webpack haben wir für Entwickler eine ressourcenschonende, innovative und unkomplizierte Möglichkeit geschaffen Insight Apps zusammenzustellen. Dies bedeutet eine Reihe von Vorteilen und Optimierungen.
Neben einer beschleunigten Ladezeit der Insight Apps, lassen sich mit Einsatz von Webpack in Zukunft Innovationen und Features (z.B. Sprachfeatures) rascher implementieren und nutzen.
Auch die Wiederverwendbarkeit von bereits existierendem Code wird dadurch vereinfacht, wodurch eine noch raschere Entwicklung ermöglicht werden kann.
Wichtige Hinweise zum Update
Falls alle der folgenden Punkte für Ihre Umgebung zutreffen:
- Verteilter Betrieb (Producer/Consumer)
- Update von einer älteren Version als 21.2 HF2 auf Version 21.2 HF2 oder neuer.
- Sequenzielles Update der Nodes (anstatt gleichzeitigen Updates), bei dem für kurze Zeit ältere und neuere Versionen gleichzeitig betrieben werden.
- Benachrichtigungen sind in mindestens einem Client Service aktiviert.
beachten Sie diese Hinweise um eine reibungslose Aktualisierung zu gewährleisten.
Sicherheitsrelevante Änderungen
21.3.5.1708
- Mitigation für CVE-2021-4034 in polkit
21.3.1.1583
- Update Apache Tomcat auf 8.5.70 (CVE-2021-33037, CVE-2021-30640)
- Update Apache Ant auf 1.9.16 (CVE-2021-36373, CVE-2021-36374)
- Fix für: ACL Internalization: ACL in Cache unterscheidet sich von DocInfo ACL
- Entfernen von Log4j2
- Fix für: NSS Security Update (CVE-2021-43527)
- httpd Security Update (CVE-2021-40438)
- Deaktiveren von mod_lua (httpd CVE-2021-44790)
Zusätzliche Änderungen
21.3.7.1714
- Fix für: Reverse-Referenzen können unter hoher Updatelast unvollständig werden
21.3.6.1711
- Fix für: Voting wird im Client angezeigt auch wenn es deaktiviert ist
21.3.5.1708
- Fix für: SharePoint Online: Delta-Tokens werden auch bei Fehlern gespeichert
- Vorschaufunktionalität kann eine definiert Dokumenteigenschaft als URL für das Abholen der Vorschau von der Datenquelle verwenden
- Snapshots: Profil kann beim Erzeugen eines neuen Snapshots ausgewählt werden
- Entfernen des DEPRECATED HANLP-Plugin
- Automatisches Vergrößern von Partitionen passend zu Disk-Größe
- Fix für: Snapshot SDK Sample OAuth-Token-Request kodiert den POST-Body nicht
- Snapshots benutzen referenzierte Ressourcen und Dev-Snapshots enthalten optional alle Ressourcen
- Authentisierte Suche mittels Subquery-Transformationen
- Verpflichtende Subqueries sind am Index konfigurierbar
- Verbesserte Bedienbarkeit des Insight Apps Designer
- LDAP Principal Cache unterstützt LDAPS (port 636)
- Sitemap Features: value format und aggregierbare Metadaten
- Fix für: GitHub Connector: Das Indizieren von öffentlichen Repositories kann zu IndexOutOfBoundsExceptions führen
- Fix für: GitHub Connector: Der “öffnen” Link von Wiki Pages funktioniert nicht
- Fix für: Salesforce Crawler und Principal Cache: 'INVALID_QUERY_LOCATOR'-Exception
- Fix für: Salesforce PermissionSetQuery liefert auch inaktive Benutzer
- Salesforce: Automatisch generierte FeedItems werden nicht indiziert
- Fix für: Salesforce: Indizieren von FeedItems kann zu IllegalArgumentExceptions führen
21.3.4.1600
- Fix für: Datumsmetadaten werden als Metrik aggregiert
21.3.3.1595
- Fix für: Reduzierte Performanz bei einer großen Anzahl von Indices
21.3.2.1592
- Fix für: CSS Probleme bei Facetten in benutzerdefinierten Insight Apps
- Fix für: Container starten in seltenen Fällen nach dem Update nicht
21.3.1.1583
- Fix für: Snapshot: invalid error response INCOMPLETE
- Verbesserungen bei Updates im Multi-Node-Betrieb
- Accessibility: Um die ARIA-Implementation für Facets – Accordion zu ändern
- Alerts: Vorschlag für 'Group' ist nicht sichtbar (overflow hidden)
- Begrenzung des Keycloak/Keycloak-HA authenticationSession Cache auf 1000 Einträge
- Binary/base64 Inhalte erkennen und bei der Invertierung ignorieren
- CRM-Berechtigungen durch Freigabe erhalten
- GPU Container Support für Fedora CoreOS (manuell installiert)
- Insight Apps Designer: Berechnete Eigenschaften sind über eine Tabellenliste editierbar
- Jira: Die Beschreibung von Jira-Tickets sollte indiziert werden. Es sollten Exclusion Pattern für Tickets definiert werden können
- Jira: Auflösen von "Project Roles" pro Projekt
- Jive Sitemap Generator: Sitemap mit Filterkriterien reduzieren
- mes:docid:<docid> bzw. `mes:docid:[docid TO docid2]` wird als Bitset dargestellt
- Microsoft Graph Connector crawled Boolean-Felder
- Microsoft Dynamics CRM: Benutzern mit dem SystemUser.IsDisabled flag den Zugang verweigern
- Mime Type Detektion: Zusätzliche Prüfung der Text-Dokumente auf Content Bytes
- Multiple CSV Logger (z.B. SharePoint Online, Exchange) verliert Einträge nach Backup
- OAuth Authentifizierung für Jive Connector
- Plugins.xml und Documentation Performance Settings (Concurrent Filter and Index Dispatch Threads) für alle Crawler
- Query Log API beinhaltet PREVIEW Aktionen
- SharePoint online: Verbesserung der Usability des Endpoint Mapping
- Sitecore Connector: Korrekte Indizierung von metadata-only Objekte
- Text Classification Service: Download Dump Button für das Herunterladen für labeled Data hinzugefügt
- Fix für: Cache Precomputation ACLs wird nicht standardmäßig true angezeigt
- Fix für: Client Service: Falsche Datenbank Credentials für Persistierte Ressourcen führen zu einem nicht reagierenden Client Service (500 Error)
- Fix für: CSV Export: Kodierungsproblem von Sonderzeichen beim Öffnen in Excel aufgrund fehlender BOM
- Fix für: Documentum Connector: Groß- und Kleinschreibung des Benutzernamens nicht beachten und dm_world für Documentum-Benutzer einschränken
- Fix für: Excel Export funktioniert nicht wenn man eingeloggt ist
- Fix für: Filteredfacet mit Data-Dropdownfitler Stil mit doppeltem Titel bei Verwendung der Data-Title Eigenschaft
- Fix für: FPDF-Filter filtert das Steuerzeichen STX nicht heraus
- Fix für: Help Linktext wird bei Verwendung vom Queryparameter ?language=de immer auf "Help" umgeschrieben
- Fix für: Index SIGSEGV in CachingAuthorizer mit Sharepoint Online
- Fix für: Jira Cache: Cache wird nie fertig aufgebaut
- Fix für: Jira Cache: Verbesserung der Cache Update Verlaufsprotokollierung
- Fix für: Jira: Crawler crawled nicht erneut, was zu erfolglosen Crawl-Läufen führen kann
- Fix für: Jira: Indiziert nicht alle verfügbaren Ausgaben. Der Zugriff auf Dokumente erfolgt mehrfach mit Paging
- Fix für: JWT-Authentifizierung funktioniert nicht für Ressourcen in zusätzlichen Kontexten
- Fix für: Korrupte Task History unterbricht Task and Node Manager
- Fix für: Label "Search App" wird in Query Performance Tests verwendet
- Fix für: LDAP Principal Resolution Cache: sehr langsam und unzuverlässig (Timeouts bei Verbindungen)
- Fix für: Mehrere Suchvorgänge werden ausgelöst, wenn der Stack geöffnet wird (Preview/Export)
- Fix für: MesUtil::BitSet ist in 64-Bit-Blöcken strukturiert. setAll(start, length) setzt immer Start bis Ende des Blocks
- Fix für: Microsoft File: Share Level ACLs verursachen STATUS_TOO_MANY_OPENED_FILES Fehler und Local Groups Resolution kann nicht deaktiviert werden.
- Fix für: Microsoft Teams Delta Bad Request & NullPointer
- Fix für: Mindbreeze Configuration: Beim Importieren von Client-Service-Konfigurationen (über die Export/Import-UI) werden Attribute, die auf Parameter gesetzt sind, auf Textwerte gesetzt
- Fix für: MMC Task: Nach Verlassen von "Tasks" wird die /find Anfrage weiterhin im Hintergrund ausgelöst
- Fix für: MultiLookupServicesDocumentIterator verwendet immer den Quellkontext vom 1. LookupServicesProvider
- Fix für: No Authorizer found for fqcategory ..." sollte im AlwaysRejectingAuthorizer protokolliert werden, wenn eine PerformAuthorization durchgeführt werden muss
- Fix für: PDF lässt sich in der Vorschau nicht downloaden
- Fix für: Reconfigure Script ist nicht robust genug, wenn mesmaster zu langsam startet
- Fix für: Reverse Proxy Timeout sind zu gering
- Fix für: SharePoint: Beim Delta Crawling werden Dokumentänderungen verpasst, aufgrund der Batch-Size ignorierter System Updates
- Fix für: SharePoint: Crawler hat aufgehört zu funktionieren (Java Prozess stehen geblieben)
- Fix für: SharePoint: Delta Crawling wird nicht beendet (Schleifenbildung auf denselben Websites)
- Fix für: SharePoint Online: Principal Cache Hoher CPU- und Speicherverbrauch. Einstellung hinzufügen, um die Prüfung zu überspringen, wenn der Cache leer ist.
- Fix für: Sitecore Connector: Fehler beim Erweitern von Field-Values für bestimmte Elemente
- Fix für: Sitecore Connector: Setzt Fallback für verwaltete Metadaten-Attribute
- Fix für: Übersetzungen im Client sind nicht vollständig
- Fix für: UPDATE_IN_PLACE aktualisiert das Dokument, auch wenn es keine Änderungen gab
- Fix für: ValueError bei DateFilterConstraint
- Fix für: Web Connector: OAuth grant_type=password_Credentials funktioniert nicht (401)