Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Query Expression Transformation
Mindbreeze Query Transformer Plugins
Mindbreeze Query Transformation
Mindbreeze stellt eine Liste von Query Transformation Services zur automatischen Modifikation von Suchanfragen für bessere Suchergebnisse bereit.
Auf der einen Seite gibt es Plugin-basierte Extension Points, die bei Bedarf in eine Mindbreeze-Installation geladen werden können:
- Synonym Transformer
- Replacement Transformer
- Auf der anderen Seite gibt es integrierte Produkt-Features, die dazu beitragen, gewünschte Suchergebnisse finden zu können (z.B. indem indizierte Dokumente mit zusätzlichen Metadaten angereichert werden):
- „Meinten Sie?“ („Did you mean?”)
- Namenerkennung (Entity Recognition)
- CSV Transformation
Query Transformation Plugins
Um eines der Query Transformation Services benutzen zu können, muss dieses zu Ihrer Mindbreeze-Installation hinzugefügt werden, indem das entsprechende Plugin geladen wird (die Query Transformation Services werden mit dem Paket “Mindbreeze Query Transformation Plugins.zip” ausgeliefert).
Das Plugin muss auch in Ihrer Mindbreeze Lizenz inkludiert sein.
Synonym Transformer Plugin
Das Synonym Transformer Plugin ermöglicht einem Suchergebnisse zu finden, indem nach verschiedenen Synonymen für ein Wort gesucht wird. Die Suchanfrage wird so transformiert, damit nach jedem Begriff in der Synonymliste gesucht wird.
Verwendung: Die Synonyme können im Mindbreeze Management Center unter „Search Experience“ > „Synonyms“ definiert werden. Dahinter liegt eine CSV-Datei, in der eine Menge an Synonyme in eine Zeile geschrieben werden, getrennt mit einem Semikolon (;).

Beispiel einer kleinen synonym.csv Datei:
auto;wagen;kraftfahrzeug
flugzeug;flieger;aeorplan
Beispiel 1: Eine Suche nach auto sendet die transformierte Suchanfrage: auto OR wagen OR kraftfahrzeug
Beispiel 2: Eine Suche nach flugzeug sendet die transformierte Suchanfrage: flugzeug OR flieger OR aeroplan
Anmerkung: Der Begriff in der ersten Spalte wird mit der Suchanfrage verglichen. Es werden nur einzelne Wörter ohne Abstände in der ersten Spalte unterstützt.
Bitte beachten Sie, dass das Plugin Synonym Transformer nicht mit dem Vocabulary Synonym Transformer verwechselt werden darf!
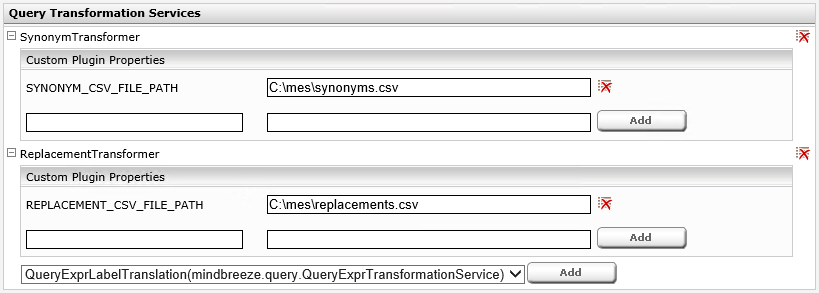
Installation
- Installieren Sie das Plugin mit der Manager UI
- Aktivieren Sie das Plugin für jeden gewünschten Index mithilfe der Manager UI:
- Wechseln Sie zum Reiter „Indices“ und aktivieren Sie „Advanced Settings“
- Scrollen Sie runter zum Abschnitt „Query Transformation Services”
- Wählen Sie das “SynonymTransformer” Plugin und klicken Sie auf „Add“
- Fügen Sie den Pfad, der zur CSV-Datei mit den Synonymdefinitionen zeigt, als “Custom Plugin Properties” hinzu.
- Fügen Sie eine neue Eigenschaft (Property) mit dem Namen SYNONYM_CSV_FILE_PATH hinzu
- Weisen Sie einen Wert mit dem Pfad zur CSV-Datei zu (entweder als lokalen Dateipfad oder als Netzwerkpfad, der für das verwendete Betriebssystem angemessen ist)
Beispiel 1: SYNONYM_CSV_FILE_PATH C:\data\synonyms.csv
Beispiel 2: SYNONYM_CSV_FILE_PATH \\fileserver.mydomain.com\mes-config\synonyms.csv
Speichern Sie schließlich die Änderungen und starten Sie die Mindbreeze Node neu, damit die Änderungen wirksam werden.
Anmerkung: Alle Änderungen in der Synonym-CSV-Datei werden sofort angewendet und werden bei der nächsten Suche miteinbezogen.
Replacement Transformer Plugin
Das ReplacementTransformer Plugin wird oft verwendet, um unangemessene Suchbegriffe mit besseren zu ersetzen oder sogar um Suchbegriffe zu verweigern.
Der Hauptunterschied zum Synonym Transformer Plugin ist, dass die originale Suchanfrage wirklich mit einer Neuen ersetzt wird, wobei sie nicht im Bericht der Suchbegriffe angezeigt wird. Der Replacement Transformer kann deswegen verwendet werden, um Suchresultate, die von Benutzern gefunden wurden, zu verbergen und ersetzt sie mit etwas anderem (z.B. Verstecken von veralteten Seiten und Zeigen der neuen Version).
Verwendung: Die zu ersetzenden Begriffe können im Mindbreeze Management Center unter „Search Experience“ > „Replacements“ definiert werden. Dahinter liegt eine CSV-Datei, wobei die erste Spalte den zu ersetzenden Begriff definiert. Die folgenden Spalten werden als mit OR getrennte Ersetzungswerte verwendet (wenn leer, wird der Begriff nicht gesucht).
Jeder neue Suchbegriff, der ersetzt werden soll, muss in eine neue Zeile geschrieben werden, wobei die Spalten mit einem Semikolon (;) getrennt werden müssen.
Beispiel für eine kleine replacement.csv Datei:
auto;mercedes;bmw;audi
party
Beispiel 1: eine Suche nach auto sendet die transformierte Suchanfrage:
mercedes OR bwm OR audi
Beispiel 2: eine Suche nach party wird keine Resultate finden, da sie mit einer leeren Suche ersetzt wird.
Installation
- Installieren Sie das Plugin mit der Manager UI
- Aktivieren Sie das Plugin für jeden gewünschten Index mithilfe der Manager UI:
- Wechseln Sie zum Reiter „Indices“ und aktivieren Sie „Advanced Settings“
- Scrollen Sie runter zum Abschnitt „Query Transformation Services”
- Wählen Sie das “ ReplacementTransformer” Plugin und klicken Sie auf „Add“
- Fügen Sie den Pfad, der zur CSV-Datei mit den Ersetzungsdefinitionen zeigt, als “Custom Plugin Properties” hinzu.
- Fügen Sie eine neue Eigenschaft (Property) mit dem Namen „REPLACEMENT_CSV_FILE_PATH“ hinzu
- Weisen Sie einen Wert mit dem Pfad zur CSV-Datei zu (entweder als lokalen Dateipfad oder als Netzwerkpfad, der für das verwendete Betriebssystem angemessen ist)
Beispiel 1: REPLACEMENT_CSV_FILE_PATH C:\data\replacements.csv
Beispiel 2: REPLACEMENT_CSV_FILE_PATH \\fileserver.x.y.com\config\REPLACEMENT.csv
Speichern Sie schließlich die Änderungen und starten Sie die Mindbreeze Node neu, damit die Änderungen wirksam werden.
Anmerkung: Alle Änderungen in der Ersetzungs-CSV-Datei werden sofort angewendet und werden bei der nächsten Suche miteinbezogen.
Generelle Anmerkungen zu den Transformer Plugins (Replacement / Synonym)
Anmerkung: Wenn Sie beide Plugins (Synonym Transformer und Replacement Transformer) verwenden, wird der Replacement-Transformer zuerst angewendet!
Die beiden Screenshots zeigen die Konfiguration der beiden Plugin auf der Mindbreeze Manageroberfläche.

Anmerkung: Alle Änderungen in den CSV Dateien werden sofort angewendet und werden bei der nächsten Suche miteinbezogen.
Stemmer Transformer Plugin
Das Stemmer Transformer Plugin erlaubt Ihnen, Suchresultate zu finden, indem nach verschiedenen Wortstämmen eines Wortes gesucht wird, basierend auf sprachliche Charakteristiken der definierten Sprache.
Verwendung: Der Basisalgorithmus, um passende Wortstämme zu finden, ist im ausgelieferten Plugin implementiert. Ein zusätzliches Wörterbuch mit Vokabularen einer bestimmten Sprache ist für die geläufigsten Sprachen verfügbar und wird verwendet, um die Suchresultate zu verbessern.
Des Weiteren können mit Hilfe des Stemmer Transformer auch sogenannte Transliterationen durchgeführt werden. Dabei werden mit Hilfe von Regeln Zeichen umgeschrieben. Es werden dann sowohl der originale Begriff als auch der umgeschriebene Begriff bei der Suche berücksichtigt.
Beispiel:
eine Suche nach blatt wird Übereinstimmungen wie blatt und blätter finden
Installation/Konfiguration
- Installieren Sie das Plugin (falls noch nicht vorhanden)
- Aktivieren Sie das Plugin für jeden gewünschten Index mithilfe der Manager UI:
- Wechseln Sie zum Reiter „Indices“ und aktivieren Sie „Advanced Settings“
- Scrollen Sie runter zum Abschnitt „Query Transformation Services”
- Wählen Sie das “ StemmerTransformer ” Plugin und klicken Sie auf „Add“
![]()
- Konfiguration der Eigenschaften (je nach Verwendung)

Languages: Die Sprachen des Stemmers. Eine oder mehrere Sprachen sind erlaubt. Die Sprachen müssen durch Komma oder Zeilenumbruch getrennt sein.
Path to vocabulary: Ein lokaler Pfad auf der Appliance der ein Vokabular enthält, damit auch die Erweiterung nicht nur die Reduktion auf Stämme durchgeführt werden kann. (zB Suche nach Baum soll auch Bäume finden).
Stemmer enabled: Wenn angehakt wird der Stemmer verwendet.
Case sensitive: Wenn angehakt wird die Reduktion der Stämme unter Berücksichtigung der Groß- und Kleinschreibung durchgeführt. Dies kann zu präziseren, aber auch weniger Stämme führen. Hinweis: das Vokabular zur Erweiterung der Stämme wird immer unter Nichtbeachtung der Groß- und Kleinschreibung verwendet.
Auto detect language from query: Der Stemmer versucht die Sprache aus der Suchabfrage abzuleiten.
Variants Boosting Factor: Definiert den Boosting Faktor für Variationen. Variantionen sind die Terms, die der Stemmer erzeugt. Dazu gehörten Stammformen, Expansionen und Transliterationen. Mit diesem Faktor beispielweise die Priorität der Variationen reduziert werden, damit die Bedeutung des Originalwerts erhalten bleibt.
Transliterate all variants: Mit dieser Option erweitert der Stemmer die Query um alle passenden Transliterationen.
TransliterationRule: Regeln zum Umschreiben von Zeichenfolgen in den Begriffen. Es können folgende Regln verwendet weden: http://icu-project.org/apiref/icu4j/com/ibm/icu/text/RuleBasedTransliterator.html
Excluded Words Path: Mit dieser Option können Sie gewisse Wörter vom Stemmen ausschließen. Erstellen Sie dazu eine Textdatei mit Wörter, welche Sie exkludieren möchten (1 Wort pro Zeile) und konfigurieren Sie den Pfad der Textdatei in der Option.
Add Single Term Alternatives as Alias: Wenn diese Option aktiviert ist, werden bei Abfragen des Typs "Terms" Synonyme für einen einzelnen Begriff (Term) als "Alias" anstelle von "Alternativen" Einträgen in der transformierten Abfrage hinzugefügt.
Speichern Sie schließlich die Änderungen und starten Sie die Mindbreeze Node neu, damit die Änderungen wirksam werden.
Anwendungsfall: Mehrsprachiges Stemmen.
Wird Mindbreeze mit mehreren Sprachen verwendet, macht es Sinn das Stemmer-Transformer Plugin für mehrere Sprachen zu konfigurieren, um überall passende Suchergebnisse zu liefern.
Mit der Konfigurationsoption „Languages“ können mehrere Sprachen konfiguriert werden. Der Stemmer versucht nun bei einer Suchanfrage für jede konfigurierte Sprache Stammformen zu finden. Alle gefundenen Stammformen aller konfigurierten Sprachen werden dann für die Transformation verwendet.
Wenn verschiedene Stammformen unterschiedlicher Sprachen zusammen verwendet werden, kann die Suche eventuell zu unscharf werden und nicht relevante Suchergebnisse liefern. Um diesen Effekt entgegen zu wirken, gibt es die Konfigurationsoption „Auto detect language from query“. Ist diese Option aktiv, wird mit einer Heuristik versucht die Sprache der Suchanfrage zu ermitteln. Hinweis: Die Heuristik ermittelt nur Sprachen, die über der Konfigurationsoption „Languages“ konfiguriert sind. Die ermittelten Sprachen werden anschließend für das Stemmen verwendet. Das bedeutet, dass nur die konkrete Sprache einer Suchanfrage zum Stemmen verwendet wird.
Damit das Expandieren der Stammformen auch mit mehreren Sprachen korrekt funktioniert, muss das Stemmer-Vokabular angepasst werden. Das Stemmer-Vokabular („Path to Vocabulary“) ist eine unsortierte Textdatei, die Wörter enthält, wobei in jeder Zeile ein Wort steht. Das Stemmer Plugin liest diese Textdatei ein und bildet Stammformen für jedes einzelne Wort und verknüpft die Informationen, welche Wörter dieselbe Stammform besitzen. Diese Informationen werden bei einer Suche zum Expandieren des Suchbegriffs verwendet. Z.B. eine Suche nach „Baum“ soll auch „Bäume“ finden. Die Sprache, welche der Stemmer beim Finden der Stammformen im Vokabular verwendet, folgt den gleichen Regeln wie beim Finden der Stammformen für einen Suchbegriff. Es werden alle konfigurierten Sprachen verwendet, oder, wenn die Konfigurationsoption „Auto detect language from query“ aktiviert ist, eine Heuristik, welche die Sprache eines Wortes im Vokabular ermittelt. Es wird empfohlen, für jede konfigurierte Sprache die Vokabular-Textdatei zu erweitern. Dies kann durch einfaches Verketten geschehen – die Wörter müssen nicht sortiert sein.
Beschränkungen des Stemmer-Transformer Plugins
Stammformen vs. Synonyme
Der Stemmer findet mit einem primitiven Algorithmus Stammformen eines Wortes und expandiert die Suchanfrage zusätzlich mit einem Vokabular. Damit werden jedoch nur geringfügige Variationen eines Worts (wenige geänderte Buchstaben) abgedeckt. Diese Funktionalität ist für die Masse der Suchanfrage sehr hilfreich, kann jedoch in speziellen Einzelfällen nicht ausreichend sein.
Falls das Expandieren eines Worts (Baum Bäume) nicht korrekt funktioniert, können folgende Maßnahmen ergriffen werden:
- Falls kein Vokabular verwendet wird, sollte ein Vokabular konfiguriert werden.
- Falls bereits ein umfangreiches Vokabular in Verwendung ist, wird empfohlen in einem Synonym-Transformer das entsprechende Wort mit Synonymen aufzunehmen. Würde man das Vokabular erweitern, bestände keine Erfolgsgarantie, da das bestehendes Vokabular meist sehr umfangreich ist und der Stemmer einen naiven Algorithmus verwendet. Fügt man jedoch ein neues Synonym hinzu, erreicht man den gewünschten Effekt auf jeden Fall.
Bekannte Wörter mit erschwerten Stemming
Es gibt einige Wörter, bei denen der Stemmer-Transformer die jeweiligen Stammformen nicht korrekt ermitteln kann. Bekannte Wörter bei der Sprache german sind: „Autos“, „Nudeln“ und „Kiwis“. Falls diese Wörter die Suchqualität beeinträchtigen, wird empfohlen, einen Synonym-Transformer zu verwenden.
Term2DocumentBoost Transformer Plugin
Das Term2DocumentBoost Plugin ermöglicht Relevance Tuning auf Suchanfragen. Sie können folgende Anwendungsfälle umsetzen:
- Für gewisse Suchanfragen die Relevanz gewisser Dokumente erhöhen. z.B. kann eine Suche nach „hilfe“ so zugeschnitten werden, damit Dokumente mit z.B. dem Schlüsselwort „Dokumentation“ bei dieser Suche eine höhere Relevanz bekommen.
- Allgemein die Relevanz gewisser Dokumente erhöhen. z.B. können alle Dokumente mit dem Schlüsselwort „Mindbreeze“ eine höhere Relevanz bekommen.
- Die Relevanz für übereinstimmende Metadaten erhöhen. z.B. wenn nach einer beliebigen Person (Suchbegriff: „Max Mustermann“) gesucht wird, können Dokumente von dieser Person (Metadatum: „Author“) eine höhere Relevanz bekommen
- Allgemein das gesamte Relevanzmodell beeinflussen. z.B ändern Sie den Relevanz Faktor „Term Frequency“, um die Priorität der Häufigkeit der Suchtreffer im Dokument zu verändern.
Installation
- Installieren Sie das Plugin mit der Manager UI.
- Aktivieren Sie das Plugin für jeden gewünschten Index mithilfe der Manager UI:
- Wechseln Sie zum Reiter „Indices“ und aktivieren Sie „Advanced Settings“
- Scrollen Sie runter zum Abschnitt „Query Transformation Services”
- Wählen Sie das “ Term2DocumentBoost ” Plugin und klicken Sie auf „Add“
- Das Plugin wird über 2 Dateien konfiguriert. Das
- „Term to Document Boost CSV File” wird benötigt für die Anwendungsfälle 1,2, und 3.
- „Default Relevance Options JSON File“ wird benötigt für den Anwendungsfall 4.

- Konfigurieren Sie die Einstellungen:
|
|
|
|
|
|
Optionale Einstellungen:
Einstellung | Beschreibung |
Use Normalization | Es wird empfohlen, diese Einstellung zu aktivieren. Ist diese Einstellung aktiviert, wird die Großschreibung von Suchbegriffen und relevanten Dokumentenstrings normalisiert und Leerzeichen werden beim Abgleich mit den Boosting-Regeln zu einem einzigen Leerzeichen zusammengefasst. |
| Es wird empfohlen, diese Einstellung zu aktivierten. Ist diese Einstellung aktiviert , werden Suchbegriffe, die unter Anführungszeichen gesetzt sind (für eine exakte Suche) auch geboostet. Ansonsten werde diese Suchbegriffe vom Boosting ausgeschlossen ignoriert. |
Speichern Sie schließlich die Änderungen und starten Sie die Mindbreeze Node neu, damit die Änderungen wirksam werden.
Konfiguration
Allgemeine Beschreibung des Term to Document Boost CSV-Dateiformats
Die Term to Document Boost CSV-Datei kann im Mindbreeze Management Center unter „Search Experience“ > „Query Boostings“ bearbeitet werden.
Die CSV-Datei beinhaltet eine Zeile für jedes Boosting, die wiederum folgenden Spalten enthält:
- Term: der Suchbegriff
- Metadata Key: der Name der Metadaten-Property, auf die das Boosting angewendet werden soll
- Pattern: ein Pattern, das den Wert bestimmt, der geboostet werden soll
- Boost: der Boost-Faktor
- Query: Optional. Erweiterte Konfiguration. Siehe Abschnitt Konfiguration via Query
Als Property können hier nur DocumentInfo Metataten (also jene die entweder aggregierbar oder regexmatchable sind) verwendet werden. Eine Liste dieser Properties ist im Designer unter „Filter“ verfügbar.
Wenn mehrere Regeln gleichzeitig übereinstimmen, wird die Regel mit dem größten Boost-Faktor verwendet. Dieses Verhalten könnte sich aber in zukünftigen Versionen ändern.
Anmerkung: Jede Änderung in der CSV-Datei wird sofort angewendet und wird in der nächsten Suche berücksichtigt.
Berechnung des finalen Wertes
Der finale Wert, womit das Boosting durchgeführt wird, entsteht durch die Multiplikation der konfigurierten Boost-Faktoren. Die verschiedenen Boost-Faktoren werden mit einem Zahlenwert definiert, wobei es Boost-Faktoren mit nur einem Zahlenwert und einem Zahlenwert und einem Exponenten gibt. Während der Basiswert des jeweiligen Boost-Faktors von der Applikation vorgegeben wird, kann der Exponent vom Nutzer bestimmt werden. Den Wert des Exponenten kann man in den folgenden Einstellungen festlegen:
- Zone Boost Exponent
- Term Boost Exponent
- Doc Boost Exponent
- Answer Doc Boost Exponent
- Term Match Exponent
- Term Boost IDF Exponent
- Term Boost Zone Coverage Exponent
Für den Exponenten kann ein Wert zwischen 0 und 1 gewählt werden. Bei einem Wert von 0 wird der Boost-Faktor deaktiviert, da dies schlussendlich einen Wert von 1 ergibt. Nachfolgend zwei Beispiele für ein besseres Verständnis.
Beispiel 1:
Anhand des eingestellten Boostings, erhält man als Basis die Zahl 4. Nun stellt man beim Term Boost Exponent einen Exponenten von 0,5 ein. Dies ergibt folgende Rechnung und schlussendlichen Wert für den Boost-Faktor:
40,5 = 2.
Dadurch wird ein finaler Boost-Faktor von 2 erzielt.
Beispiel 2:
Anhand des eingestellten Boostings, erhält man als Basis die Zahl 10. Dadurch, dass die Einstellungen für den Exponenten (z. B. Zone Boost Exponent) nicht weiter konfiguriert wurden, besitzt der Exponent den Wert 0. Dies ergibt folgende Rechnung:
100 = 1.
Damit besitzt der finale Boost-Faktor den Wert 1, wodurch dieser Boost-Faktor deaktiviert ist.
Empfohlene Boost-Faktoren
Der empfohlene Bereich für die Boost-Faktoren befindet sich zwischen 1 und 10. Wird ein höherer Faktor verwendet, können weitere Feinabstimmungen unbeabsichtigt beeinflusst werden. Die Verwendung eines Boost-Faktors zwischen 1 und 10 kann in den folgenden Funktionen angewandt werden:
- Zone Boosting
- Document Boosting
- Term Boosting
Für mehr Informationen, siehe Mindbreeze Query Expression Transformation - Zone Boostings (Boosting von Metadaten) , Mindbreeze Query Expression Transformation - Document Boosting (Alternative zu Term to Document Boost CSV) und Mindbreeze Query Expression Transformation - Term Boosting (Term and NGram Boosts).
Schnellstart-Guide für die Konfiguration
In diesem Kapitel wird ein grober Überblick über die notwendigen Schritte zum Konfigurieren des Boostings gegeben. Dabei gilt, dass umfassendes Testen notwendig ist, um die festgelegten Boost-Faktoren zu überprüfen und abzustimmen. Folgende Schritte müssen durchgeführt werden:
- Konfiguration der Relevance Factors (falls Standardwerte nicht ausreichen)
- Optionale Konfiguration des Document Boostings
- Optionale Konfiguration des Zone Boostings
- Optionale Konfiguration des Term Boostings
- Optionale Konfiguration des Additive Document Boostings
Die Relevance Factors stellen die Basiskonfiguration des Boostings dar und sind dementsprechend essentiell für alle Anwendungsfälle. Die Standardwerte sind für die meisten Anwendungsfälle ausreichend. Sollte eine Änderung der Standardwerte notwendig sein, müssen die neuen Werte umfassend getestet werden. Da Relevance Factors globale Einstellungen sind, kann die Änderung der Werte bereits konfigurierte Boostings beeinflussen. Mehr Informationen zu den Relevance Factors finden Sie in Mindbreeze Query Expression Transformation - Relevance Factors (Term Frequency, Document Frequency).
Nach den Relevance Factors kann das Boosting durch die Konfiguration des Document Boostings, Zone Boostings und Term Boostings feiner eingestellt werden. Hierbei wird als erste Zusatzkonfiguration das Document Boosting empfohlen, da dies einfach durchgeführt werden kann. Auch hier gilt es die eingestellten Werte ausreichend zu testen, um die Position des Dokuments in den Suchergebnissen zu überprüfen. Zusätzlich sollten auch irrelevante Suchen durchgeführt werden, um die Position des Dokuments auch in solchen Fällen zu überprüfen. Entsprechend den Ergebnissen müssen die eingestellten Werte in Document Boosting erneut angepasst werden.
Sollte es Metadaten geben, wo die Übereinstimmung stärker gewichtet sein soll, wird Zone Boosting empfohlen. Falls komplexere Konfigurationen benötigt werden, sollte Term Boosting verwendet werden. Sind alle benötigten Konfigurationen durchgeführt, kann der Personalized Relevancy Transformer für weitere Feinabstimmungen verwendet werden. Die Konfiguration des Additive Document Boostings wird je nach Anwendungsfall empfohlen.
Anwendungsfall: Für gewisse Suchanfragen die Relevanz gewisser Dokumente erhöhen
Beispiel der CSV-Datei:
Term;Metadata Key;Pattern;Boost
help;title;portal help|intranet help;5
Wenn ein Benutzer nach help sucht, werden Dokumente, die im Titel die Begriffe portal help oder intranet help enthalten, mit dem Faktor 5 geboostet.
Anwendungsfall: Allgemein die Relevanz gewisser Dokumente erhöhen
Term;Metadata Key;Pattern;Boost
;extension;.*pdf;10
Lassen Sie die Spalte “Term” leer. Das Dokument wird ohne Rücksicht auf die Suchanfrage des Benutzers geboostet. Z.B. kann jedes Dokument mit der Erweiterung „pdf“ hoch- bzw. runter-geboostet werden.
Einführung in das Mindbreeze Relevanzmodell
Das Mindbreeze Relevanzmodell berechnet für jedes Resultat einen sogenannten Relevanzcount (rank). Dieser ist auch als Metadatum im Mindbreeze Export ersichtlich:
Dieser Relevancecount berechnet sich auf folgenden Parametern. Umso höher der Count umso wichtiger ist das Resultat.
Recency
Umso aktueller ein Resultat ist umso höher wird der Relevancecount
Term Frequency
Umso öfter der gesuchte Term im aktuellen Treffer matched umso höher wird der Relevanzcount.
Term Proximity
Ist der Abstand zwischen den vorkommenden Matches im aktuellen Resultat geringer als in einem anderen so ist dieses wichtiger.
Term Inverse Zone Frequency
Wen 2 Dokumente die gleiche Anzahl an Matches vorweist jedoch in einem Dokument viele mehr andere Begriffe vorkommen als im anderen. So bekommt das Dokument mit der geringeren Anzahl an anderen Begriffen einen höheren Rang.
Bekannte Missverständnisse Fehlerinterpretationen
Wichtig dabei anzumerken ist, dass Boosting den Relevanzcount nicht ersetzte, sondern ihn nur Multiplikativ erhöht. Ist der Relevanzcount eines Dokumentes 20 und es wird mit Faktor 2 geboostet, ist die Relevanz nachher 40. Dies kann zu folgenden Phänomen führen. Sie möchten Resultat 2 auf Stelle 1 haben:
Resultat 1: Rank=2000
Resultat 2: Rank=20
Boostern sie Resultat 2 dann mit 10 wird es immer noch genauso an Stelle 2 sein als vor dem Boosting:
Resultat 1: Rank=2000
Resultat 2: Rank=200
Sie müssen daher Resultat 2 beispielsweise um Faktor 101 Boosten um es an erster Stelle zu bekommen
Resultat 2: Rank=20020
Resultat 1: Rank=2000
Anwendungsfall: Die Relevanz für Übereinstimmende Metadaten erhöhen / Erweiterte Konfiguration mit Query
Um mehr Flexibilität über das Boosting zu haben, können Sie alternativ eine weitere Spalte „Query“ hinzufügen. Hier können Sie direkt mit der Mindbreeze InSpire Query Language eine Query angeben, welche die zu boostenden Dokumente bestimmt.
Hinweis: Wenn Sie die Spalte „Query“ verwenden, werden die Spalten „Metadata Key“ und „Pattern“ ignoriert.
Beispiel eines Query Boosting innerhalb des MMC Tabelleneditor:
Term | Metadata Key | Pattern | Boost | Query |
help | 3 | "datasource/mes:key":"http://myweb.com/help-index.html" |
Wenn ein Benutzer nach help sucht, werden Dokumente, welche mit der Query "datasource/mes:key":"http://myweb.com/help-index.html" gefunden werden, mit dem Faktor 3 geboostet.
Eine weitere Einsatzmöglichkeit des Query Boosting ist, wenn man nach Personennamen sucht, sollen diejenigen Dokumente geboosted werden, welche von der gesuchten Person verfasst wurden.
Dazu wird das Metadatum des Dokuments „Author“ zur Hilfe genommen. In den Boosting Regeln steht uns die Variable {{query}} zu Verfügung, die in diesem Fall den Wert der gesuchten Person entspricht.
Somit können wir für diesen Fall eine Query Definieren, die Dokumente mit Autor des gesuchten Begriffes findet, und diese boostet.
Die Variable {{query}} wird in der Query-Spalte verwendet und wird dynamisch bei einer Suche durch die Such-Query ersetzt.
Hinweis: wenn Sie die Spalte Query verwenden, wird auch die Spalte Term ignoriert.
Wenn der Benutzer nach dem Begriff Max Mustermann sucht werden anhand dem darunter stehenden Boosting, alle Dokumente welche mit dem Author-Metadatum: Max Mustermann um 7 geboosted.
Term | Metadata Key | Pattern | Boost | Query |
7 | Author:"{{query}}" |
Ein weitere nützliche Variable, die man einsetzen kann, ist die {{lang}} Variable.
Wenn der Benutzer eine Suche startet, sollen diejenigen Dokumente geboosted werden, welche der Webbrowser-Sprache des Benutzers entsprechen.
Dazu wird ein Dokument-Metadatum benötigt, in der die Sprache des Dokuments gespeichert ist.
Um dies zu bewerkstelligen, muss das LanguageDetector Plugin konfiguriert werden. Der LanguageDetector kann dann erkennen, in welcher Sprache ein Dokument geschrieben ist und setzt das zugehörige Sprachen-Metadatum (Beispiel: en oder de).
Die Variable {{lang}} enthält die Sprache, welche in der Query vom Webbrowser gesendet wird.
Hinweis: Auch hier wird die Spalte Term ignoriert, wenn man die Spalte Query verwendet.
Wenn der Benutzer nun beispielsweise ein LanguageDetector Plugin konfiguriert, welches ein Metadatum mit dem Namen detectedLanguage erstellt, werden anhand dem darunter stehenden Boosting alle Dokumente, die der Sprache des Webbrowsers entsprechen, um 7 geboosted.
Term | Metadata Key | Pattern | Boost | Query |
detectedLanguage | {{lang}} | 7 |
Folgende weitere Variablen werden unterstützt:
Name | Beschreibung |
{{query}} | Der aktuelle Suchbegriff |
{{lang}} | Die Sprache im User-Context (z.B. en) (falls vorhanden) |
{{country}} | Das Land im User-Context (z.B. US) (falls vorhanden) |
{{usercontext_language}} | Der Language-Code User-Context (z.B. en-US) (falls vorhanden) |
{{session_<<key>>}} | Beliebige Werte aus der Session des User-Contexts. z.B. {{session_mycustomkey}} ergibt mycustomvalue (falls in den Session-Properties vorhanden) |
{{identity_name}} | Name des Benutzers im User-Context. (z.B. john.doe) (falls vorhanden) |
{{identity_<<key>>}} | Beliebige Werte aus der Identity des Benutzers. z.B. {{identity_mail}} ergibt john.doe@example.com (Falls in den Identity-Properties vorhanden) |
{{usercontext_<<key>>}} | Beliebige Werte aus dem User-Context. z.B. {{usercontext_mycustomkey}} ergibt mycustomvalue (falls in den User-Context Properties vorhanden) |
Falls für eine Variable kein Wert vorhanden ist, wird das zugehörige Boosting nicht angewandt.
Anwendungsfall: Allgemeine Beeinflussung des Relevanzmodells
Sie können allgemein sämtliche Parameter des Relevanzmodells anpassen. Dies geschieht über die Default Relevance Options JSON Datei.
Es wird nicht empfohlen diese JSON-Datei manuell zu editieren. Stattdessen gibt es im Management Center unter dem Menüpunkt „Search Experience“ den Punkt „Relevance“.
Hinweis: Diese Parameter sind fundamentaler Bestandteil des Relevanzmodells, geringe Änderungen können große Auswirkungen auf die Reihenfolge der Suchergebnisse haben. Es ist möglich, dass die Boosting-Faktoren im CSV nachträglich angepasst werden müssen.
In den folgenden Abschnitten wird beschrieben, welche Parameter angepasst werden können.
Für weitere Informationen siehe:
- Handbuch Konfiguration Mindbreeze InSpire, Registerkarte Indices
- Handbuch api.v2.search Schnittstellenbeschreibung
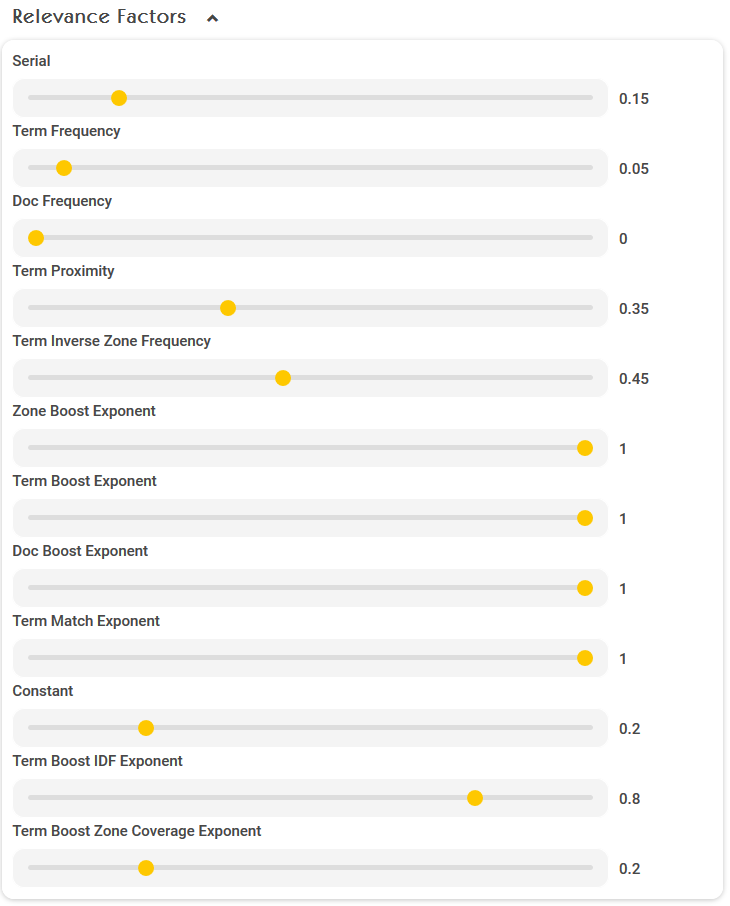
Relevance Factors (Term Frequency, Document Frequency)
- Mit den einzelnen Eingaben kann festgelegt werden, welchen Einfluss die Relevanzparameter auf die Relevanzbewertung haben. Der relative Anteil der einzelnen Faktoren ist der prozentuelle Anteil dieses Parameters.
Faktor | Beschreibung |
Serial | Der Einfluss der Aktualität (Dokumentdatum mes:date) auf die Relevanz. Als „aktuell“ werden Dokumente der letzten 2 Jahre (25 Monate) gewertet. Alles was älter als 2 Jahre ist, wird generell als nicht aktuell behandelt. |
Term Frequency | Absolute Häufigkeit der Wörter |
Doc Frequency | Relative Häufigkeit der Wörter im Dokument – TF-IDF |
Term Proximity | Abstand der getroffenen Begriffe zueinander im Text |
Term Inverse Zone Frequency | Maximale relative Häufigkeit der Wörter in einzelnen Zonen – max TF-IZF |
Similarity | Definiert den Einfluss der Relevanzbewertung der NLQA Antworten auf die Relevanzbewertung des Suchtreffers. |
Zone Boost Exponent | Einfluss des Dokumenteigenschafts-Boosting auf die Relevanzbewertung (0 bedeutet wird ignoriert) |
Term Boost Exponent | Einfluss des Suchbegriffs-Boosting auf die Relevanzbewertung (0 bedeutet wird ignoriert) |
Doc Boost Exponent | Einfluss der mes:boost Eigenschaft auf die Relevanzbewertung (0 bedeutet wird ignoriert) |
Answer Doc Boost Exponent | Einfluss der Eigenschaft „mes:boost“ auf die Relevanzbewertung der NLQA Antworten (= score im api.v2.search Response). Der Wert 0 bedeutet, dass dieser Faktor ignoriert wird. |
Similarity Weight For Reranking Exponent | Einfluss des originalen similarity_score (api.v2.search Response) auf die Relevanzbewertung der NLQA Antworten (= score im api.v2.search Response), wenn Answer Reranking aktiviert ist. Der Wert 0 bedeutet, dass dieser Faktor ignoriert wird. |
Reranked Answer Doc Boost Exponent | Einfluss der Eigenschaft „mes:boost“ auf die Relevanzbewertung der NLQA Antworten (= score im api.v2.search Response), wenn Answer Reranking aktiviert ist. Der Wert 0 bedeutet, dass dieser Faktor ignoriert wird. |
Term Match Exponent | Einfluss der Übereinstimmung von Terms (interessant bei Veroderung) mes:boost Eigenschaft auf die Relevanzbewertung (0 bedeutet wird ignoriert) |
Constant | Wenn insbesondere ausschließlich Term Boosting / Document Boosting / Zone Boosting verwendet wird und man nicht z. B. auf die restlichen Komponenten (z.B. Term Proximity, Serial) zurückgreifen möchte |
Term Boost IDF Exponent | IDF = Inverse Document Frequency. Die Häufigkeit des Vorkommens eines Begriffs in vielen Dokumenten soll eine Auswirkung auf die Berechnung des Term Boosts haben. Hoher Exponent heißt: seltene Wörter werden stärker gewichtet. Niedriger Exponent heißt: häufige Wörter werden schwächer gewichtet. 0 bedeutet, dass diese Option ignoriert wird. |
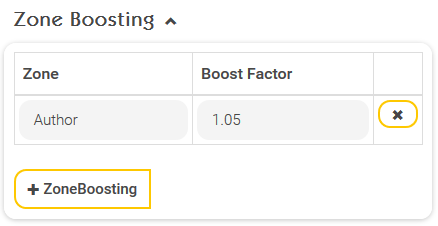
Zone Boostings (Boosting von Metadaten)

Zone Boosting ist eine weitere Variante, um die Reihenfolge der Suchergebnisse verändern zu können. Dabei können für sogenannte „Zonen“ Boost-Faktoren konfiguriert werden. Eine Zone ist nichts Anderes wie ein Metadatum eines Dokuments. Möchte man also, dass Dokumente, die aufgrund eines gewissen Metadatums gefunden werden, in den Suchresultaten weiter nach oben gereiht werden, kann für dieses Metadatum (=Zone) ein Boost-Factor definiert werden. Im obigen Beispiel werden Dokumente, die Aufgrund des Metadatums „Author“ gefunden werden, um den Faktor 1,05 relevanter eingestuft. Gültige Werte des Boost Factors sind reelle Zahlen größer oder gleich eins mit Dezimaltrennzeichen „.“ (≥ 1.0).
Document Boosting (Alternative zu Term to Document Boost CSV)
Mithilfe von “Document Boosting” kann die Relevanz von bestimmten Dokumenten auch verändert werden. Die Relevanz von Dokumenten, die aufgrund eine Suchanfrage gefunden werden, kann für alle Dokumente um den “Boost Factor” verändert werden, die mit der “Query Expr” übereinstimmen. Im obigen Beispiel werden gefundene Dokumente, die vom Autor “Legend User” stammen, um den Faktor 1,1 relevanter eingestuft.
Gültige Werte des Boost Factors sind:
- Für Verminderung der Gewichtung: reelle Zahlen größer als null und kleiner als eins (> 0.0 ∧ < 1.0) mit Dezimaltrennzeichen „.“
- Für Erhöhung der Gewichtung: reelle Zahlen größer als eins (> 1) mit Dezimaltrennzeichen „.“
- Der Boost Factor 1 hat keine Auswirkung
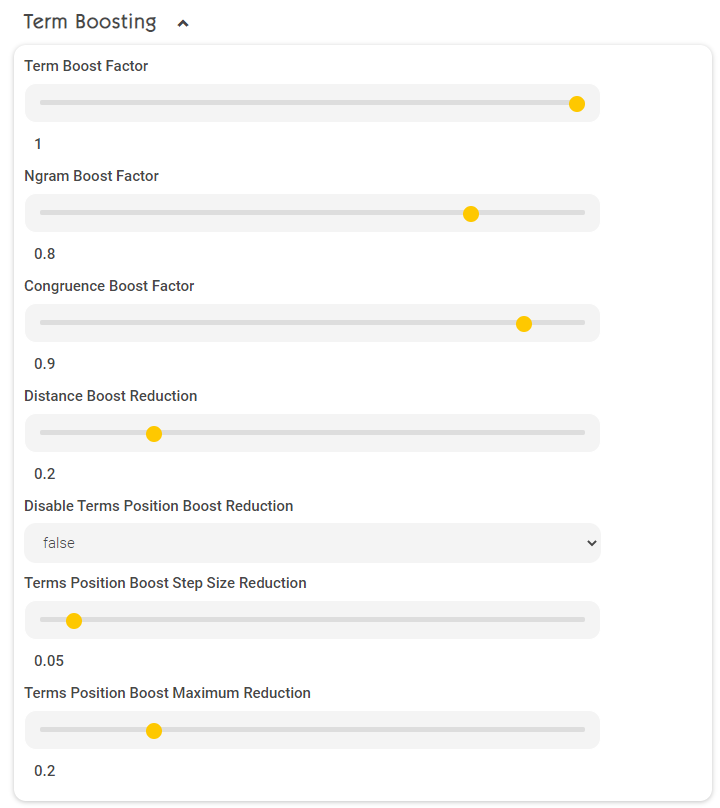
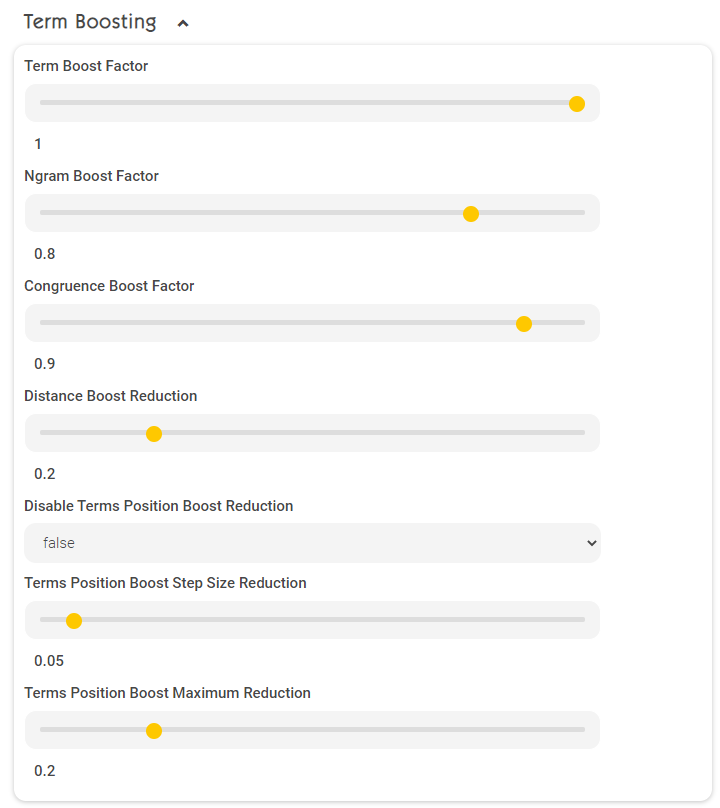
Term Boosting (Term and NGram Boosts)
Faktor | Beschreibung |
Term Boost Factor | Boost-Faktor für exakte Matches (1.0) |
Ngram Boost Factor | Boost-Faktor für Teilwort-Matches (1.0). Diese Option ist nur relevant, wenn im Management-Center unter „Configuration” -> „Client Services” -> „Enable Character NGRAMs” („Advanced Settings” müssen aktiv sein) aktiviert ist. Standardmäßig ist diese Option bereits aktiviert. |
Congruence Boost Factor | Boost Faktor für Character-Kongruenz (z.B. „a“ vs. „ä“). Diese Option ist nur relevant, wenn im Management-Center unter „Configuration” -> „Client Services” -> „Query Expansion for Diacritic Term Variants” (“Advanced Settings” müssen aktiv sein) aktiviert ist. Standardmäßig ist diese Option bereits aktiviert. |
Distance Boost Reduction | Boost Abnahme je Änderung = Edit-Distance (z. B. „Mindbreze” vs „Mindbreeze”). Diese Option ist nur relevant, wenn im Management-Center unter „Configuration” -> „Client Services” -> „Enable Query Expansion for Similar Term” (“Advanced Settings” müssen aktiv sein) aktiviert ist. Standardmäßig ist diese Option jedoch deaktiviert. |
Disable Terms Position Boost Reduction | Wenn “true” warden die Einstellungen „Terms Position Boost Step Size Reduction“ und „Terms Position Boost Maximum Reduction“ deaktiviert. |
Terms Position Boost Maximum Reduction | Maximaler Wert, um den das Boosting eines Terms verringert werden kann. Werte: 0.0 – 1.0 (Default 0.2) Beispiel: Hinweis: „Terms Position Boost Maximum Reduction“ funktioniert nur, wenn Optional Terms in Client Services aktiviert ist (standardmäßig aktiviert). |
Terms Position Boost Step Size Reduction | Schrittgröße, um den jeder folgende (rechtsstehende) Wert verringert wird. Beispiel bei 0.1 und „Terms Position Boost Maximum Reduction“=0.2 und Sucheingabe von „Ich heiße Max Mustermann“ ergibt folgende Term Boosting: Hinweis: „Terms Position Boost Step Size Reduction“ funktioniert nur, wenn Optional Terms in Client Services aktiviert ist (standardmäßig aktiviert). |
Other Relevance Options

Option | Beschreibung |
Using Additive Document Boosting (Recommended) | Bestimmt die Boosting-Strategie bei mehrfachen Boostings eines Dokuments. Standardmäßig ist das „Additive Document Boosting“ aktiviert, welche alle Boostings auf einem Dokument zum Berechnen der Relevanz berücksichtigt. Falls die Einstellung deaktiviert ist, wird nur das jeweils höchste Boosting zum Berechnen der Relevanz verwendet. |
Use Additive Zone Boosting (Experimentell) | Legt die Boosting-Strategie für mehrere Zonen-Boostings fest. Standardmäßig ist diese Option deaktiviert und nur das am besten passende Zone Boosting wird berücksichtigt. Wenn die Option aktiviert ist, werden alle übereinstimmenden Zone Boostings bei der Berechnung der Relevanz berücksichtigt. |
Export Dump
Der aktuelle Dump kann mit über den Button „Download Dump“ als Excel File gespeichert und heruntergeladen werden.

MetadataQueryTransformer Plugin
(ehemals „MetadataTransformer“ Plugin) Diese Plugin manipuliert Suchanfragen für Suchen nach Metadaten. Es wird eingesetzt für Benutzer die mit Doppelpunkt-Notation suchen (z.B. name:John), aber damit nicht das Metadatum „name“ meinen. Das Plugin wird mit einer CSV-Datei bestehend aus Regeln konfiguriert.
Installation
- Installieren Sie das Plugin mit der Manager UI
- Aktivieren Sie das Plugin für jeden gewünschten Index mithilfe der Manager UI:
- Wechseln Sie zum Reiter „Indices“ und aktivieren Sie „Advanced Settings“
- Scrollen Sie runter zum Abschnitt „Query Transformation Services”
- Wählen Sie das „MetadataQueryTransformer ” Plugin und klicken Sie auf „Add“
Konfiguration
Folgende Parameter können konfiguriert werden:
Parameter | Beschreibung |
Path to Label transformation CSV | Pfad zur CSV-Datei (siehe nächster Abschnitt) |
Asterisk Expansion Vocabulary File | Pfad zur Vokabular-Datei (siehe nächster Abschnitt) |
Asterisk Expansion Max Results | Maximale Anzahl von Wörtern, die das Stern-Symbol expandiert |
Label Transformation CSV Syntax
Diese Datei beinhaltet die Transformationsregeln. Eine Regel pro Zeile. 2 oder mehr Spalten ohne Spaltenbeschriftung. Bedeutung der Spalten:
Label | Name des Labels in der Suchanfrage, für den diese Regel gilt. Hier kann auch das Sternsymbol (*) für beliebige Namen verwendet werden. |
Regeltyp | „PHRASE”, „NEAR”, „IGNORE”, „REGEX_PATTERN” oder „ASTERISK_PATTERN” |
Optionen | Je nach Regeltyp |
Grundsätzlich wird direkt im Metadatum gesucht und alternativ eine alternative Suchbedingung hinzugefügt.
Hinweis: Für die Typen REGEX_PATTERN oder ASTERISK_PATTERN sollte die durchsuchte Eigenschaft regexmatchable oder aggregatable sein. Dies kann im Category Descriptor oder in der Index Konfiguration definiert werden.
Regeltyp | Beschreibung |
PHRASE | Erzeugt eine Phrasen-Suche (normale Suche). z.B: Regel name;PHRASE , Suche nach „name:John“ findet Dokumente mit „name John“ im Inhalt. |
NEAR | Erzeugt eine Near-Suche, der Abstand ist über eine Option definierbar. z.B. Regel temperature;NEAR;3 , Suche nach „temperature:20“ findet Dokumente mit „the temperature is about 20 degrees“ im Inhalt. |
IGNORE | Erzeugt eine Neutrale Suche, die selbst keine Ergebnisse liefert. z.B. Regel operation:IGNORE Diese Regel erlaubt es ein selektives Ausnehmen von Transformationen, wenn zuvor mittels * eine Standard-Transformation eingeführt wurde. |
ASTERISK_PATTERN | Transformiert eine Metadatensuche in eine Asterisk-Pattern Suche, Synonyme sind über Optionen definierbar. z.B. Regel number;ASTERISK_PATTERN;id;nb , Suche nach „number:A42*“ findet Dokumente, dessen Eigenschaft „id“ oder „nb“ mit A42 beginnt. |
REGEX_PATTERN | Erzeugt eine Regex-Pattern Suche, Synonyme sind über Optionen definierbar z.B. Regel number;REGEX_PATTERN;id;nb , Suche nach „number:A.*“ findet Dokumente, dessen Eigenschaft „id“ oder „nb“ mit dem regulären Ausdruck A.* übereinstimmt. |
Vocabulary File Syntax
Unabhängig von der Label Transformation, bietet das Plugin auch die Fähigkeit normale Suchbegriffe, die Sternsymbole (*) enthalten zu transformieren. Dabei werden diese Suchbegriffe durch ähnliche Begriffe aus einem definierten Vokabular ersetzt.
Das „Vocabulary File“ ist eine Textdatei mit Begriffen, ein Begriff pro Zeile.
Zum Beispiel bei einem Vocabulary File mit folgendem Inhalt:
superprint
printomatic
fastprint
wird bei einer Suche nach „*print“ nach Folgenden Begriffen gesucht: „superprint“ und „fastprint“.
DotExtensionToLabeledTransformer Plugin
Dieses Plugin erleichtert das Suchen nach einer Dateiendung. Suchanfragen in der Form „.pdf:suchbegriff“ werden in die Form „extension:pdf suchbegriff“ umgewandelt.
Beispiel: Eine Suche nach dem Begriff „Invoice“ und der Dateiendung „pdf“ sieht normalerweise so aus:
„extension:pdf Invoice“
Mit diesem Plugin lässt sich die Suche vereinfachen auf
„.pdf:Invoice“
Installation
- Installieren Sie das Plugin mit der Manager UI
- Aktivieren Sie das Plugin für jeden gewünschten Index mithilfe der Manager UI:
- Wechseln Sie zum Reiter „Indices“ und aktivieren Sie „Advanced Settings“
- Scrollen Sie runter zum Abschnitt „Query Transformation Services”
- Wählen Sie das “ DotExtensionToLabeledTransformer” Plugin und klicken Sie auf „Add“
- Speichern Sie schließlich die Änderungen und starten Sie die Mindbreeze Node neu, damit die Änderungen wirksam werden.
Installation
Das QueryExprLabelTranslation Plugin ist bereits eingebaut (built-in) und erfordert keine Installation.
Konfiguration
Dieses Plugin benötigt keine Konfiguration.
QueryExprLabelTranslation Plugin
Das Plugin ermöglicht es nach Metadaten in der Originalsprache zu suchen. Beispielsweise ist das Metadatum mit der ID „title“ im Deutschen übersetzt als „Name“. Will man nach Dokumenten mit dem Namen „Rechung“ suchen, muss man ohne diesem Plugin folgende Suchanfrage stellen – „title:Rechnung“ – um die gewünschten Ergebnisse zu erhalten. Mit dem QueryExprLabelTranslation Plugin kann nun auch eine Suchanfrage in der Originalsprache gestellt werden: „Name:Rechnung“. Das verwendete Label „Name“ wird vom Plugin zurückübersetzt auf „title“ und die Suchanfrage liefert wieder die gewünschten Ergebnisse.
Konfiguration
Das QueryExprLabelTranslation Plugin ist standardmäßig für jeden Index aktiv und erfordert keine Konfiguration. Die Übersetzungen werden aus dem CategoryDescriptor von den metadatum-Tags geladen.
Zusätzliche Features
Did you mean? (Meinten Sie?)
Wenn Sie keine Resultate finden oder das Wort in der Suche nur falsch geschrieben haben, bietet Mindbreeze einen alternativen Suchbegriff an (basierend auf interne Indexstatistiken und –analysen), die bessere Ergebnisse finden würden. Diese Feature heißt „Did you mean?“.
Entity Recognition (Namenserkennung)
Entity Recognition kann verwendet werden, um Metadaten vom Dokumenteninhalt oder von anderen Metadateneigenschaften des Dokuments zu extrahieren, damit diese später für effizientere Suchen verwendet werden können.
Dieses Thema wird in der Dokumentation – Mindbreeze Inspire im Detail beschrieben. Für Details lesen Sie bitte das Kapitel Registerkarte „Indices“ in der Dokumentation.
CSV Transformation
Um indizierte Dokumente mit zusätzlichen Metadaten für einfacheres Finden von Ergebnissen zu erweitern, erlaubt die CSV Transformation das Abbilden von klar definierten Werten auf andere Werte, die in der CSV-Datei gespeichert sind.
Dieses Feature kann sehr hilfreich sein, um Ihren Index mit technischen Begriffen, Abkürzungen, Themen oder sogar kurzen Beschreibungen zu Ihren Dokumenten in speziellen Fällen zu erweitern.
Beispiel: Postleitzahlverzeichnis
ZIP;City;Province
4020;Linz;Oberösterreichischer Zentralraum
1020;Wien;Hauptstadt von Österreich
9861;Krems;Waldviertel
4400;Steyr;Traunviertel
Die erste Zeile dieser Beispiel-CSV-Datei beinhaltet die Spaltennamen, um die Daten darauf abzubilden. Die anderen Zeilen beinhalten die Werte für jede Spalte. Wenn Sie also nach dem Begriff “viertel” suchen, werden Sie als Suchresultat die beiden Städte Steyr und Krems finden.
Ein anderes Beispiel wäre das Abbilden von technischen Produktdaten der Artikel Ihrer Website in einer CSV-Datei. Das Abbilden dieser Daten könnte realisiert werden, indem die Produkt-IDs von den Artikeln Ihrer Website extrahiert und verwendet werden, wobei die CSV-Datei dann eine Menge an Spalten enthält, die ein Produkt beschreiben kann (Produkt-ID, Kategorie, Preis, Größe, etc.).
Konfiguration
Alle diese Features sind Teile des Mindbreeze Basisprodukts, bei denen Sie keine zusätzlichen Plugins benötigen, jedoch müssen Sie die Features folgendermaßen konfigurieren:
- Wechseln Sie zum Reiter „Indices“ und aktivieren Sie „Advanced Settings“.
- Scrollen Sie runter zum Abschnitt „CSV Transformationen“
- Spezifizieren Sie den Pfad zur CSV-Datei, die die Mappings beinhaltet (entweder als Pfad im lokalen Dateisystem oder als Netzwerkpfad, der für das verwendete Betriebssystem angemessen ist.
- Beispiel 1: CSV File PathC:\data\csv-mappings.csv
- Beispiel 2: CSV File Path\\fileserver.x.y\config\csv-mappings.csv
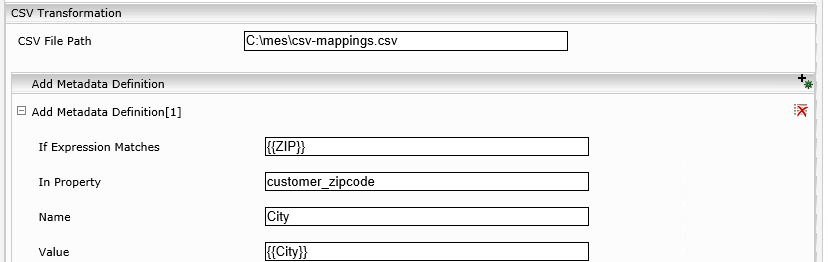
Für jede Metadateneigenschaft (Property, in den Spalten), die Sie von der CSV-Datei extrahieren wollen, müssen Sie eine neue Metadatendefinition (in “Add Metadata Definitions”) mit den folgenden Property-Settings hinzufügen:
- If Expression Matches:{{ZIP}}… dies ist der Name der Spalte in der CSV-Datei, der als Schlüssel dienen soll, um Dokumente darauf abzubilden.
- In Property:customer_zipcode … dies ist die Metadaten-Property des indizierten Dokuments, die mit dem angegebenen Wert in „If Expression Matches“ verglichen wird (hier könnte z. B. auch mes:key oder eine andere Property verwendet werden).
- Name:City… dies ist der Name der gewünschten neuen Property in den Metadaten. Dieser wird beim Suchen verfügbar sein und wenn im categoryDescriptor gelistet, wird dieser auch in den Suchresultaten sichtbar sein.
- Value:{{City}}… die ist der Name der gewünschten Zielspalte in der CSV-Datei (Überschrift der Spalte, die extrahiert werden soll).
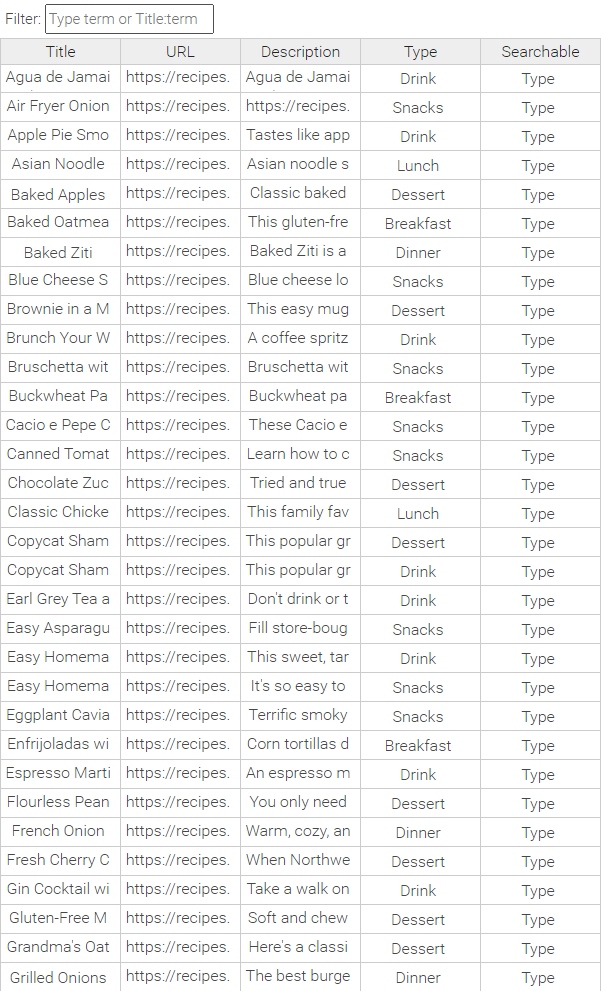
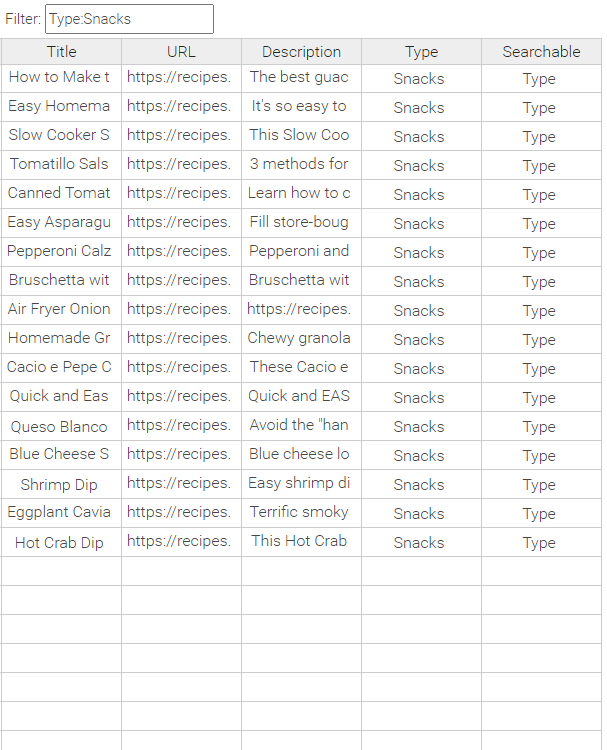
Filtern im CSV-Editor
Wenn Sie die Daten einer CSV-Editor-Tabelle während des Filterns speichern, werden die gesamten Tabellendaten gespeichert, einschließlich der nicht gefilterten Datensätze.
Sie können filtern, indem Sie einen Suchbegriff ohne Berücksichtigung der Groß-/Kleinschreibung eingeben, der in allen Spalten gesucht wird. Außerdem können Sie den Suchumfang eingrenzen, indem Sie in einer bestimmten Spalte suchen. Spaltenname:Suchbegriff findet Treffer nur aus der jeweiligen Spalte. Sowohl beim Spaltennamen als auch beim Suchbegriff wird die Groß-/Kleinschreibung nicht berücksichtigt.
Beispiel 1: Keine Filterung der Daten
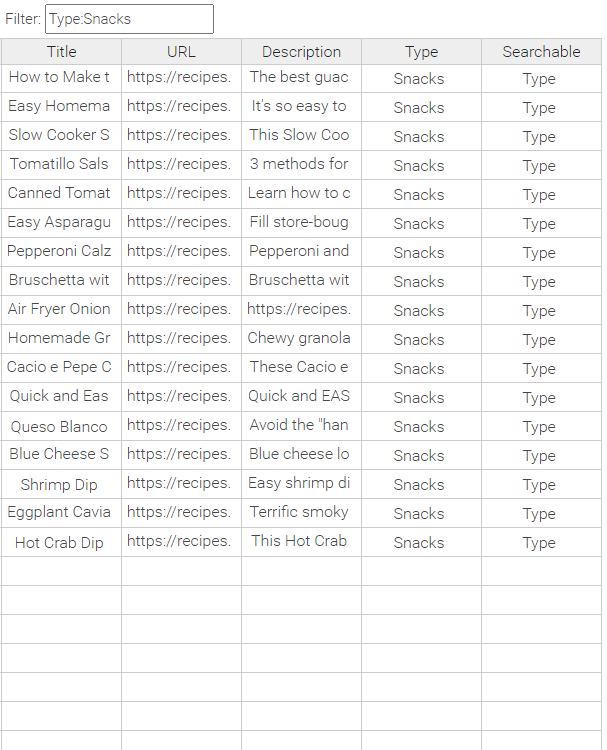
Beispiel 2: Alle Datensätze mit Type „Snacks“ werden angezeigt