
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Metadaten-Anreicherung
Konfiguration
Allgemein
Damit die Anreicherungsverfahren angewendet werden, müssen die neuen Metadaten zuerst am Index zu den Aggregated Metadata Keys hinzugefügt werden.
Zum Beispiel:

Entity Recognition
Einführung
Dieses Kapitel beschäftigt sich mit dem Konzept, dem Setup und den Troubleshooting-Methoden für die Konfiguration von Entity Recognition.
Konfiguration - Entity Recognition
In diesem Kapitel wird das Konzept von Entity Recognition anhand eines einfachen Beispiels erklärt. Führen Sie zum Einrichten folgende Schritte durch:
- Verbinden Sie sich zum Management Center
- Navigieren Sie zu dem Configuration Menü und dann zum Index Tab.
- Aktivieren Sie die Advanced Settings und öffnen Sie die Indexeinstellungen des Index, den Sie mit Entity Recognition konfigurieren möchten.
- Suchen Sie nach den „Entity Recognition Parameter“-Einstellungen.
- Definieren Sie ihre Entity Recognition Regeln im Feld „Pattern-Rules“, die Ihrem Metadatum matchen sollen.
- Folgende Regelformate werden unterstützt: https://github.com/google/re2/wiki/Syntax
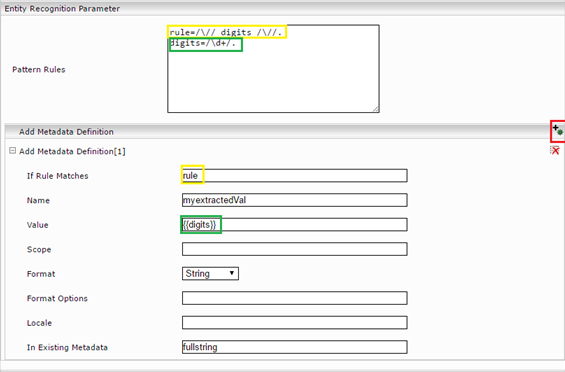
- In unserem konkreten Beispiel:
rule=/\// digits /\//.
digits=/\d+/.
Erklärung:
Die erste Regel definiert, dass alle Zahlen zwischen zwei Slashes matchen sollen (Regex).:
Beispiel: test/1234test1234/test/543/test (543 wird extrahiert)
Fügen Sie nun eine neue „Metadata Definition“ hinzu, um die Regeln für Metadaten anzuwenden.
Beispiel:
In diesem Beispiel sucht Mindbreeze im String des existierenden Metadatums "fullstring“ nach Zahlen zwischen 2 Slashes. Sind Zahlen zwischen 2 Slashes vorhanden, dann nimmt Mindbreeze den Teil der Matches, der in der Subregel „digits" konfiguriert ist und schreibt diesen als String in das neue Metadatum „myextractedVal“.
Beispiel:
fullstring: xyz/1234/herbert543/345test
Match der Regel “rule”: /1234/
Wert der Regel “digits”: 1234
Wert des Metadatums myextractedVal==1234
Hinweise zur Konfiguration im Management Center
Bei der Konfiguration als Metadatum in Mindbreeze InSpire müssen folgende Felder befüllt werden:
Feld | Beschreibung |
If Rule Matches | Name der Regel. |
Name | Name des Metadatums. |
Value | Wert der Regel. Beispiel: „{{Monat}}“ – kann auch normaler Text sein oder zusammengesetzt sein Bsp.: „Datum {{Tag}}.{{Monat}}.{{Jahr}}“. |
Format | Format der Regel. „String“, „Date“, „Number“. |
Format Options | Formatierungs-Optionen – vor allem bei Datum wie bei Simpledateformat. |
In Existing Metadata | Bereich, wo die Regel angewendet wird z.B.: content, title, datasource/mes:key, <eigenes Metadatum>, …). |
Scope | Mit der Einstellung Scope ist es möglich, einen Bereich/mehrere Bereiche mit einer Entity Recognition Regel zu selektieren, in denen die Regeln für die Extraktion angewendet werden sollen. Dazu wird der Name der Regel für die Selektierung des Bereiches/der Bereiche in das Feld „Scope“ eingetragen. Im Gegensatz zur Werteextraktion müssen Sie hier den Namen ohne {{}} eingeben. |
Entity Recognition (Beispiel: Filesystem)
Dieses Kapitel beschäftigt sich mit der Einrichtung und Erklärung von Entity Recognition mit Mindbreeze unter Anlehnung an ein einfaches Beispiel.
Konfiguration von Entity Recognition für ein Filesystem:
share=/[^\\]+/.
directory=/[^\\]+/.
UNCPath="\\\\" host "\\" share "\\" directory "\\".
Metadata-Definition 1:
Wert | |
If Rule Matches | UNCPath |
Name | Laufwerk |
Value | {{share}} |
In Existing Metadata | datasource/mes:key |
Metadata-Definition 2:
Wert | |
If Rule Matches | UNCPath |
Name | Projektpfad |
Value | {{directory}} |
In Existing Metadata | datasource/mes:key |
Aggregated Metadata Keys (; separated) | Laufwerk;Projektpfad |
Datums-Formate für Entity Recognition basieren auf den ICU-Patterns (z.B. Locale … de_AT).
Konfiguration für Entity Recognition für Filesystem Pfade (2 Varianten) – mit Ausnahmen:
Sind die Regeln mehrdeutig, kann über alternative Regeln und einer Reihung durch Benennung sowie die korrekte Reihung der mehrfachen Metadaten-Extraktion auch solch ein komplexer Fall erreicht werden. Der Pfad (path) als Metadatum ist lower-case und somit besser für CSV-Mapping.
Hinweis: Ein ODER (|) von Sub-Regeln funktioniert nicht!
- Einfache Lösung ohne Ausnahme:
Pattern Rules:
LWPath=/\\\\[^\\]+\\[^\\]+\\[^\\]+\\[^\\]+/.
FilePath=/[^\\]+/.
FullPath=LWPath "\\" FilePath.
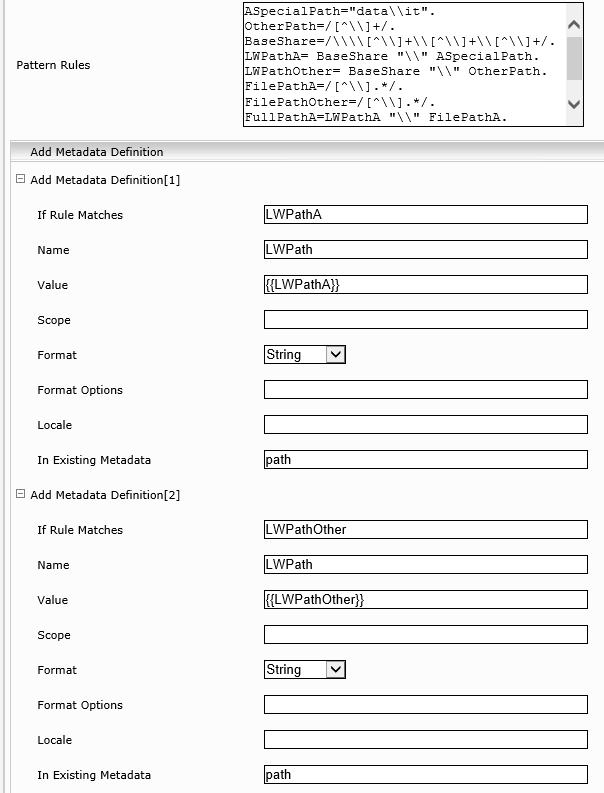
Lösung mit einer Ausnahme (data\it):
Pattern Rules:
ASpecialPath="data\\it".
OtherPath=/[^\\]+/.
BaseShare=/\\\\[^\\]+\\[^\\]+\\[^\\]+/.
LWPathA= BaseShare "\\" ASpecialPath.
LWPathOther= BaseShare "\\" OtherPath.
FilePathA=/[^\\].*/.
FilePathOther=/[^\\].*/.
FullPathA=LWPathA "\\" FilePathA.
FullPathOther=LWPathOther "\\" FilePathOther.
Im nachstehenden Screenshot wird die Konfiguration der Regeln visualisiert.

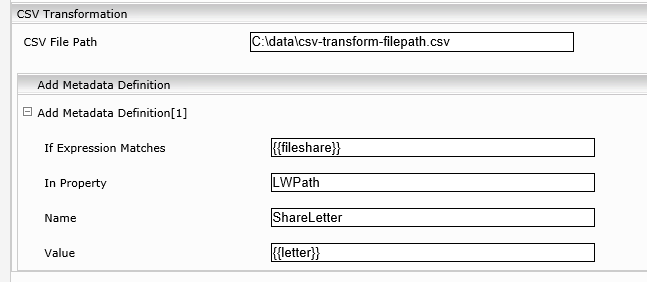

CSV-Transform: der extrahierte Wert (fileshare) muss case-sensitive matchen, somit sollte der path als Quell-Metadatum verwendet werden.
fileshare;letter
\\fileserver.myorganization.com\qa\fstest\projekte;U:
\\fileserver.myorganization.com\qa\fstest\vorlagen;T:
\\fileserver.myorganization.com\qa\fstest\allgemein;G:
\\fileserver.myorganization.com\qa\fstest\spezial;M:
\\fileserver.myorganization.com\qa\fstest\data\it;H:
\\fileserver.myorganization.com\qa\fstest\data;H:
\\fileserver.myorganization.com\qa\fstest\data-services;H:
\\fileserver.myorganization.com\qa\fstest\allgemein-retail;G:
Hinweis: Match auf mes:key geht in CSV-Transformation (sowie in ER-rules) nur mit: In Property = datasource/mes:key.
Achtung: /documents-Servlet liefert keine Werte, die nur über Index Re-Invert entstehen!
Troubleshooting Entity Recognition
Dieses Kapitel beschäftigt sich mit dem Troubleshooting der Entity Recognition Regeln.
Wichtige Hinweise
- In Mindbreeze InSpire werden die regulären Ausdrücke zusätzlich mit einem „/“ umschlossen.
- Dabei muss jeder Regeleintrag durch einen Punkt getrennt sein.
- Regelnamen dürfen keine „_“ beinhalten
- Regeln sind greedy (= gierig – matchen so viel wie möglich Achtung bei „.*“ bzw. „.+“ Konfigurationen)
- Regeln werden alphabetisch abgearbeitet (Groß-/Kleinschreibung beachten!)
Zuerst kommen Großbuchstaben von A bis Z, danach Kleinbuchstaben a bis z. - Trifft eine Regel einen Bereich, so kann keine zweite Regel treffen Annahme: Befindet sich sowohl in Gremium als auch in Schlagwort das Wort „Vorstand“, so wird nur das Metadatum mit der Regel „Gremium“, das Wort „Vorstand“ beinhalten
- Entity Recognition Rules können nur pro Index, also über alle darin befindlichen Datenquellen angelegt werden.
Index
Den Status des Index kann man mit dem Index-Servlet „Statistics Information“ abfragen. Bevor das Index-Servlet verwenden werden kann, müssen bestimmte Voraussetzungen erfüllt werden. Siehe dazu Konfiguration - Index-Servlets - Voraussetzungen.
Für mehr Informationen zum Index-Servlet, siehe Konfiguration - Index-Servlets - Statistics Information (/statistics).
Privileged Servlets
Mit dem Index-Servlet „Entity Recognition Workbench“ können Regeln entworfen und mit dem aktuell aktiven Index ausprobiert werden. Bevor das Index-Servlet verwenden werden kann, müssen bestimmte Voraussetzungen erfüllt werden. Siehe dazu Konfiguration - Index-Servlets - Voraussetzungen.
Für mehr Informationen zum Index-Servlet „Entity Recognition Workbench“, siehe Konfiguration - Index-Servlets - Entity Recognition Workbench (/processitems).
Deaktivierung von gierigem Verhalten der Entity Recognition Regeln
Entity Recognition Regeln sind normalerweise gierig. Im folgenden Beispiel werden die markierten Zeilen gematcht:
Regel
R1=/ (?s)(test)(?P<line>.+)\s+(.*Page) /.
Match:
Wird „greedy“ deaktiviert würde jedoch nicht mehr alles gematchet werden, sondern nur jene Blöcke die mit test beginnen und mit Page enden:
Regel:
(?U)(?s)(test)(?P<line>.+)\s+(.*Page)(?U)
Match:
Häufige Fehlerursachen
Bei der folgenden Fehlermeldung ist ein Fehler beim Parsen der ER-Regeln aufgetreten:
“MesQuery::Text::RE2Tokenizer ERROR: Matched empty (epsilon) token, pattern is”
… z.B. wird ein „\“ am Ende einer Regex nicht unterstützt (LWPath=/\\\\[^\\]+\\/. … und liefert einen Fehler. Besser: LWPath=/\\\\[^\\]+/ “\\“.).
Eventuell kann es auch zu Problemen mit “.*“ in Regeln kommen.
Entity Recognition Rules werden in alphabetischer Reihenfolge ausgewertet und der erste vollständige Match gewinnt.
Regex-Rules nach deutschen Wörtern treffen mit \w nicht alle Zeichen (Umlaute, etc.). Stattdessen können Sie mit \pL alle Unicode-Buchstaben matchen.
Typische Anwendungsfälle
Personal Information
SVNR
\d{4}(\s|\.|\-)\d{6}
Beispiel
1237 010180
1237.010180
1237-010180
Telephone number
(\+)([\s.\(\)]*\d{1}){8,13}(-)?(\d{1,5})
Beispiel
+43 732 606162-0
+43 732 606162-609
+49(732)606162-609
Number (With delimiters)
RegEx
z1=/\d/.z2=/\d/. (…)Dlmtr=/[\s\-_.:]?/.
z1 Dlmtr z2 Dlmtr z3 Dlmtr z4 Dlmtr z5 Dlmtr z6.
Example
12-34567
12 34 56-7
1-2 3456.7
Amount
((\d{1,3}(\.(\d){3})*)|\d*)(,\d{1,2})
Example
0,84
100.000,49
100.000,00
1.000.000.000.000,00
Datum
Handbuch zu den Datumsformaten: http://userguide.icu-project.org/formatparse/datetime
- dd(.|-|/)MM(.|-|/)yyyy
- RegEx
((0[1-9])|[1-9]|([1-3][0-9]))(\.|\/|-)((0[1-9])|[1-9]|10|11|12)(\.|\/|-)((19|20)\d{2}) - Beispiel
11.03.2014
11.3.2014
3.3.2014
03.2.2010
11/03/2014
11/3/2014
3/3/2014
03/2/2010
11-03-2014
11-3-2014
3-3-2014
03-2-2010
- RegEx
- dd. MMM yyyy
- RegEx
((0[1-9])|[1-9]|([1-3][0-9]))\..(|Januar|Februar|März|April|Mai|Juni|Juli|August|September|Oktober|November|Dezember).((19|20)\d{2}) - Example
3. Jänner 2014
4. Februar 2012
30. November 2013
- RegEx
- MMM yyyy
- RegEx
(Januar|Februar|März|April|Mai|Juni|Juli|August|September|Oktober|November|Dezember).((19|20)\d{2}) - Example
Februar 2014
September 2014
- RegEx
- MM(.|-|/)yyyy
- RegEx
(Januar|Februar|März|April|Mai|Juni|Juli|August|September|Oktober|November|Dezember).((19|20)\d{2})|((0[1-9])|[1-9]|10|11|12)(\.|\/|-)((19|20)\d{2}) - Example
03-2014
03.2014
03/2014
- RegEx
- yyyy(.|-|/)mm(.|-|/)dd
- RegEx
((19|20)\d{2})(\.|\/|-)((0[1-9])|[1-9]|10|11|12)(\.|\/|-)((([1-3][0-9]|0[1-9])|[1-9])) - Example
2014-03-21
- RegEx
- Datums-Regex Gesamt
((0[1-9])|[1-9]|([1-3][0-9]))(\.|\/|-)((0[1-9])|[1-9]|10|11|12)(\.|\/|-)((19|20)\d{2})|((0[1-9])|[1-9]|([1-3][0-9]))\..(Januar|Februar|März|April|Mai|Juni|Juli|August|September|Oktober|November|Dezember).((19|20)\d{2})|(Januar|Februar|März|April|Mai|Juni|Juli|August|September|Oktober|November|Dezember).((19|20)\d{2})|((0[1-9])|[1-9]|10|11|12)(\.|\/|-)((19|20)\d{2})|((19|20)\d{2})(\.|\/|-)((0[1-9])|[1-9]|10|11|12)(\.|\/|-)((([1-3][0-9]|0[1-9])|[1-9])) - Datums-Regex Gesamt II
((((0?[1-9]|[12]\d|3[01])[\.\-\/](0?[13578]|1[02])[\.\-\/]((1[6-9]|[2-9]\d)?\d{2}))|((0?[1-9]|[12]\d|30)[\.\-\/](0?[13456789]|1[012])[\.\-\/]((1[6-9]|[2-9]\d)?\d{2}))|((0?[1-9]|1\d|2[0-8])[\.\-\/]0?2[\.\-\/]((1[6-9]|[2-9]\d)?\d{2}))|(29[\.\-\/]0?2[\.\-\/]((1[6-9]|[2-9]\d)?(0[48]|[2468][048]|[13579][26])|((16|[2468][048]|[3579][26])00)|00)))|(((0[1-9]|[12]\d|3[01])(0[13578]|1[02])((1[6-9]|[2-9]\d)?\d{2}))|((0[1-9]|[12]\d|30)(0[13456789]|1[012])((1[6-9]|[2-9]\d)?\d{2}))|((0[1-9]|1\d|2[0-8])02((1[6-9]|[2-9]\d)?\d{2}))|(2902((1[6-9]|[2-9]\d)?(0[48]|[2468][048]|[13579][26])|((16|[2468][048]|[3579][26])00)|00)))) - Example
31.12.2005
12.12.12
1.2.2003
1.3.98
04-05-2004
Zeit
(([0-1]?[0-9])|([2][0-3])):([0-5]?[0-9])(:([0-5]?[0-9]))?
Example
11:00:23
12:30
Email
([a-zA-Z0-9_\-\.]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})
Example
david.porter@inspire.mindbreeze.com
egov@mindbreeze.com
IBAN
AT\d{18}
Example
AT002105017000123456
Kommagetrennte Liste von Inhalten
In diesem Beispiel wird eine Liste von Inhalten getrennt mit einem Beistrich als Liste in Mindbreeze interpretiert.
Input: Liste aus Wort, Wort,
Wert=/[^\s,][^,]*[^,\s]?/.
Regel= /\s*/ Wert /\s*(,\s*|$)/.
Kataloganreicherung
Es werden neue Metadaten zu einem Dokument hinzugefügt. Die neuen Metadaten werden mithilfe eines „Katalogs“ (z.B. CSV-Datei) erzeugt.
Hier werden folgende Möglichkeiten beschrieben:
- Index CSV-Transformation (Funktionalität im Index bereits vorhanden)
- HierarchicalCSVEnricher (separates ItemTransformation Plugin)
- FileMetadataEnricher (separates ItemTransformation Plugin)
Index CSV-Transformation
Dieser Abschnitt beschäftigt sich mit der Anreicherung der Metadaten mithilfe eines CSV-Files. Dabei ist es möglich einen Wert eines Metadatums mit dem Wert einer bestimmten Spalte im CSV zu vergleichen. Stimmt der Wert aus dem Metadatum mit dem Wert aus der Spalte überein kann man den Wert einer anderen Spalte aus derselben Zeile in ein neues Metadatum schreiben und dem Resultat anfügen.
Einrichtung der CSV-Transformation
Dieses Kapitel beschäftigt sich mit der Einrichtung von CSV Transformation anhand eines konkreten Beispiels. Für die Konfiguration müssen folgende Schritte durchgeführt werden:
Verbinden sie sich mit dem Mindbreeze Management Center (Default: https://IhreAppliance:8443 )
Navigieren sie zum Indices Tab, aktivieren sie die Advanced Settings und Erweitern sie den gewünschten Index
Suchen sich nach der Einstellung „CSV Transformation“ und richten sie die Funktion wie im nachstehenden Beispiel ein
Example:
Einstellung | Beschreibung | Beispiel |
CSV File Path | Pfad des von Ihnen kopierten CSV-Files am Server. | /data/MedicationsActiveIngredientsUTF8_UNIX.csv |
Add Metadata Definition | ||
If Expression Matches | Name der Spalte im CSV, die mit dem Wert eines Metadatums übereinstimmen muss, damit die Transformation ausgeführt wird. | {{Medication}} |
In Property | Das existierende Metadatum, das mit dem Wert aus der Spalte im CSV vergleicht werden soll. | medication |
Name | Name des Metadatums, welches den neu angereicherten Wert enthalten soll. | ATC_CODE |
Value | Name der Spalte, dessen Wert in das neue Metadatum „Name“ geschrieben werden soll um das Resultat damit anzureichern
| {{ATC_CODE}} |
Wie funktioniert es?
Der Wert des existierenden Metadatums(„medication“) wird mit dem Wert aus der Spalte „Medikament“ verglichen. Wurde eine Zeile gefunden, bei der beide Werte äquivalent sind, so wird der Wert aus der Spalte ATC_CODE extrahiert und dem Metadatum ATC_CODE hinzugefügt.
Änderungen im CSV-File mittels Tabellenverarbeitungsprogramm
Wenn Sie das CSV mit einem Tabellenverarbeitungsprogramm wie Microsoft Excel bearbeiten, müssen Sie sicherstellen, dass das CSV nach der Bearbeitung immer noch im Format UTF8 und nicht UTF8-BOM ist.
Dies können sie mit einem beliebigen Texteditor, wie zum Beispiel Notepad++, überprüfen und gegebenenfalls zurück in das Format UTF8 umwandeln.

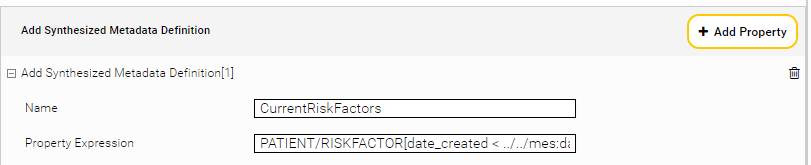
Synthesized Metadata
Mithilfe von Synthesized Metadata Definitions können Regeln erstellt werden, um Dokumente mit Metadaten anzureichern. Diese Regeln werden zum Zeitpunkt der Suche dynamisch ausgewertet.

Beschreibung | |
Name | Name des synthetisierten Metadatums. |
Property Expression | Ausdruck in Mindbreeze Property Expression Language, der zum synthetisieren des Metadatumwerts verwendet wird. |
Precomputed Synthesized Metadata
Mithilfe von Precomputed Synthesized Metadata Definitions können Regeln erstellt werden, um Dokumente mit Metadaten anzureichern. Diese Regeln werden während der Index-Invertierung ausgewertet, um Metadaten zu synthetisieren.
Bitte beachten Sie, dass bei Precomputed Synthesized Metadata Definitions nur eine Teilmenge der Mindbreeze Property Expression Language unterstützt wird. Alle Ausdrücke in Mindbreeze Property Expression Language - Spezifische Sprachelemente für die Suche werden nicht unterstützt, was auch Ausdrücke, die Referenzen enthalten, wie Pfade oder inverse Referenzen betrifft. Wenn Sie Ausdrücke mit Referenzen verwenden wollen, können Sie stattdessen Synthesized Metadata Definitions erstellen.
Bitte beachten Sie, das vordefinierte Metadaten, wie mes:key, Category, CategoryInstance und FQCategory nicht für Precomputed Synthesized Metadata Definitions verfügbar sind. Stattdessen können Synthesized Metadata verwendet werden.

Folgende Einstellungen stehen zur Verfügung
Einstellung | Beschreibung |
Name | Name des synthetisierten Metadatums |
Property Expression | Ausdruck in Mindbreeze Property Expression Language, der zum synthetisieren des Metadatumwerts verwendet wird. |
Transformation Pipeline Slot | Definiert, an welcher Stelle das Metadatum in der Semantic Pipeline synthetisiert werden soll. Folgende Optionen stehen zur Verfügung:
|
Merge Strategy | Folgende Optionen stehen zur Verfügung:
|
Aggregatable | Definiert, ob das synthetisierte Metadatum aggregierbar sein soll. Folgende Optionen stehen zur Verfügung:
|
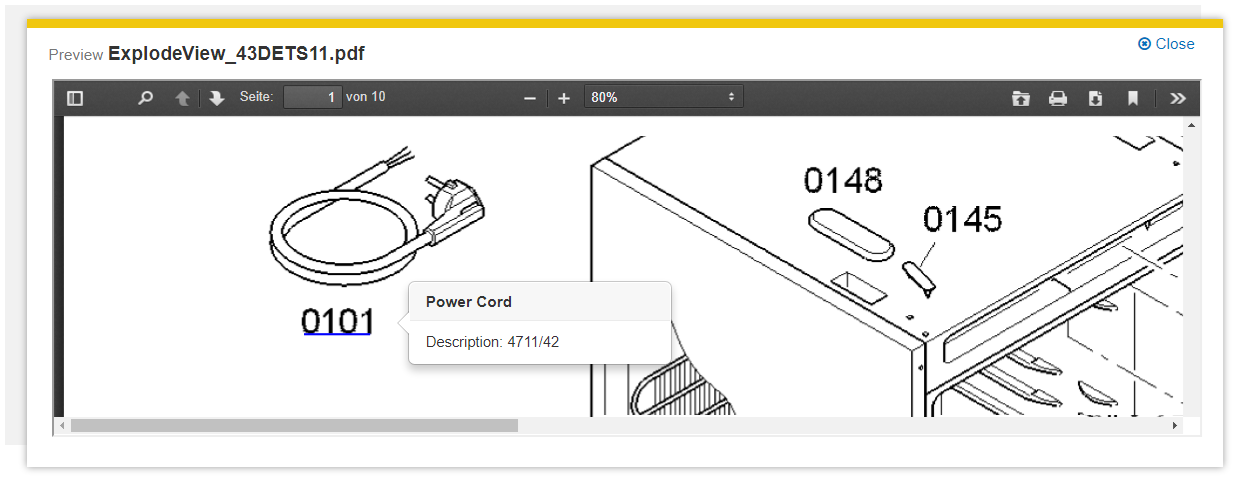
Hierarchical CSV Enricher (ItemTransformer.HierarchicalCsvEnricher)
Einleitung
Dieses Plugin annotiert in PDF Dokumenten spezielle Wörter, die in einer CSV-Datei angegeben sind. Diese annotierten Wörter (Matches) werden in der PDF-Vorschau als klickbare Hyperlinks dargestellt. An diese Hyperlinks können in einen Custom-Client eigene Aktionen gekoppelt werden. Beispielsweise kann bei einem Mouse-Over über ein spezielles Wort eine Erklärung als Tooltipp eingeblendet werden. Zusätzlich kann das Plugin für Matches Metadaten generieren und Entities annotieren.
Installation
Um das Plugin zu benutzen, muss das MetadataTransformationService Plugin zu Ihrer Mindbreeze-Installation hinzugefügt werden, in dem das entsprechende Plugin geladen wird.
Konfiguration
Das Plugin wird grundsätzlich als eigenständiger Service gestartet. (Ähnlich zu Caching Principal Resolution Services). In den Indices werden Referenzen auf den Service konfiguriert. Das Plugin selbst wird im Abschnitt „Services“ konfiguriert:
- Aktivieren Sie das Plugin für jeden gewünschten Index mithilfe der Management UI:
- Wechseln Sie zum Tab „Indices“ und akivieren Sie „Advanced Settings“.
- Scrollen Sie runter zum Abschnitt „Services”.
- Wählen Sie das Plugin “ItemTransformationServicePlugin.HierarchicalCsvEnricher“ aus und klicken Sie auf „Add“.
Grundeinstellungen
Einstellung | Beschreibung |
Text Pipeline Service | |
Display Name | Für eine einfache Zuordnung zum Index wählen Sie hier einen möglichst beschreibenden Namen. |
Nodes | |
Nodes | Wählen Sie die Node aus, auf dem der Service laufen soll. Nur Indices auf derselben Node können den Service nutzen. |
Base Configuration | |
Bind port | Ein freier TCP-Port, welcher von keinem anderen Service belegt ist. |
Max Threads | Die maximale Anzahl von Threads, die der Dienst bei der Bearbeitung von Anfragen verwenden darf. |
CSV Transformation Configuration

Einstellung | Beschreibung |
Transformation Timeout (ms) (Advanced Setting) | Definiert das Timeout (in ms), wo nach dem Ablaufen der Zeit die Transformation abgebrochen wird. Die bis zu diesem Zeitpunkt transformierten Metadaten bleiben erhalten. Standardwert: 250000 ms. |
Document Exclusion Rules | Regeln, welche die Transformation von Dokumenten mit gewissen Metadaten überspringen. Siehe Abschnitt unten |
CSV File Path | Pfade zu den CSV Dateien. In der ersten Zeile der CSV Datei werden Spaltenbeschriftungen erwartet. Mit dem Knopf „Add“ können mehrere CSV Dateien hinzugefügt werden. Die CSV Dateien werden nach einer Änderung automatisch neu eingelesen. |
CSV Delimiter Character | Das CSV-Trennzeichen. Ein Buchstabe. (Üblicherweise Semikolon) |
Term Colum Name | Name der CSV-Spalte, welche für das „Matching“ in den Dokumenten verwendet wird. |
Name der CSV Spalte, welche für das annotieren von Entities in den Dokumenten verwendet wird. (Nicht kompatibel mit „Entity Value“) | |
Entity Value | Statischer Wert, welcher bei allen Matches als Entity-Annotation hinzugefügt wird. (Nicht kompatibel mit „Entity Column Name“) |
Bestimmt das Metadatum, aus dem der Text für das „Matching“ stammt. Wenn diese Einstellung leer ist, so wird der Text des Dokuments für das „Matching“ verwendet (Standard). | |
Enable Build Hierarchy | Das Plugin kann mit dieser Option in einen Hierarchie-Modus geschaltet werden. Dazu muss das CSV eine Eltern-Kind-Beziehung zwischen den Einträgen besitzen, welche über eine weitere Spalte, die zum Eltern-Eintrag zeigt abgebildet ist. Als Metadatum-Wert wird dann die Hierarchie selbst verwendet. |
Parent Column Name | Name der CSV-Spalte, die zum Eltern-Eintrag (dort die Term-Column) zeigt. Diese Option ist nur wirksam, wenn Enable Build Hierarchy aktiviert ist. |
Skip Root Element | Wenn diese Option aktiviert ist, wird die Wurzel (root) der Hierarchie nicht zum Metadatum-Wert hinzugefügt. |
Target Metadata Name | Name des Metadatums, welches erzeugt wird. |
Target Metadata Name Pattern | Vorlage-Muster aus dem der Name des Metadatums erzeugt wird. In Platzhaltern können die CSV-Spaltennamen in doppelt geschwungenen Klammern verwendet werden, zum Beispiel: {{Meta Name}}. |
Target Metadata Value Pattern | Vorlage-Muster aus dem der Wert des Metadatums erzeugt wird. In Platzhaltern können die CSV-Spaltennamen in doppelt geschwungenen Klammern verwendet werden, zum Beispiel: {{Term Name}} (nicht Hierarchie-Modus). |
Merge Strategy | Hier kann die Lösungsstrategie definiert werden, falls es schon ein Metadatum mit dem gleichen Namen gibt. Entweder „Keep Existing“ oder „Overwrite Existing“ |
Overlapping Match Strategy | Wenn an einer Stelle im Dokument mehrere, sich überlappende, Übereinstimmungen gefunden werden, wird mit dieser Option bestimmt, welche Übereinstimmungen schlussendlich verwendet werden. Es stehen 2 Strategien zur Verfügung: „Longest“ verwendet nur die längste Übereinstimmung (Anzahl Buchstaben). Hinweis: wenn „All“ verwendet wird, können in Kombination mit der Option „Link HREF Pattern“ sich überlagernde Annotationen entstehen. |
Target Metadata Property Constraints | Hier können Bedingungen angegeben werden, unter welche ein Metadatum-Wert hinzugefügt wird. Die Bedingungen entsprechen den Item Properties und werden als eine kommagetrennte Liste von Key-Value Paaren konfiguriert, wobei die Key-Value Paare mit einem Gleichheitszeichen getrennt werden, zum Beispiel: name=bob,person=true. Diese Funktion wird üblicherweise verwendet, um zu verhindern, dass Metadatum-Werte, die ohnehin in den Attribut-Metadaten enthalten sind, zu den („normalen“) Metadaten hinzugefügt werden. Der Standardwert ist leer. (alle Werte werden hinzugefügt) |
Target Metadata Item Name | Name des „Item“ Metadatums. Das Plugin kann zusätzlich ein komplexes Metadatum erzeugen, welches für alle Matches die zugehörigen CSV-Einträge beinhaltet. Zusätzlich werden für jeden CSV-Eintrag eine Liste von Vorkommnissen mit Properties geführt. |
Target Metadata Item Default Properties | Hier können für das Metadatum Item die Standardwerte der Properties im Vorkommnis definiert werden. Die Properties werden als eine Komma-getrennte Liste von Key-Value Paaren konfiguriert, wobei die Key-Value Paare mit einem Gleichheitszeichen getrennt werden. |
Link HREF Pattern | Vorlage-Muster aus dem die URL erzeugt wird, mit der das PDF-Dokument annotiert wird. Die CSV-Spaltennamen können in Platzhaltern mit doppelt geschwungenen Klammern verwendet werden, zum Beispiel: http://www.example.com/{{Term Name}}. Hinweis: Die URL muss valide sein. Der Wert des Platzhalters wird URL-encoded. Damit die URL auch in der PDF Vorschau angezeigt wird, muss in den Einstellungen des jeweiligen Index bei „Aggregated Metadata Keys“ der Wert „@content“ hinzugefügt werden. |
Add Additional HREF Link HTML Annotation | Wenn diese Option aktiviert ist, werden für HREF Links zusätzliche HTML-Tags erstellt. Dadurch funktionieren die Links auch in anderen Dokument-Previews als PDF, wie z.B. HTML oder docx. Dabei werden auch alle Annotationen aggregiert. Wenn diese Option aktiviert werden soll, muss zusätzlich in dem jeweiligen Index ein Precomputed Synthesized Metadatum über den Content gesetzt werden:
„Transformation Pipeline Slot“ und „Aggregatable” können auf dem Default Wert belassen werden. |
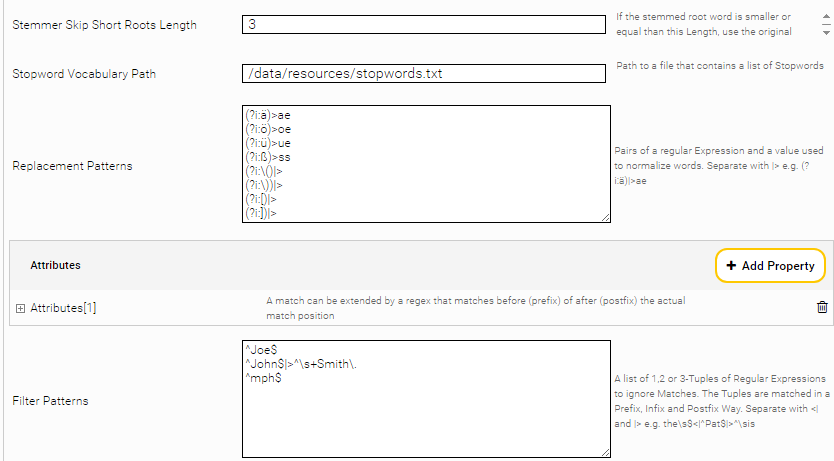
Enable Stemmer | Aktiviert den Stemmer. Dadurch erhöht sich die Matching-Anzahl, da auch die abgewandelten Formen von Wörtern Matches erzeugen. |
Stemmer Language | Sprache des Stemmers. Z.B. german, english, russian |
Stemmer Skip Short Roots Length | Beim Einsatz des Stemmers können False-Positive Matches entstehen, wenn Wörter in der Stammform zu kurz werden. Diese Einstellung bestimmt, dass der Stemmer bei sehr kurzen Stammformen nicht verwendet wird. Definiert wird die minimale Länge der Stammform, ab der der Stemmer nicht mehr verwendet wird. |
Stopword Vocabulary Path | Pfad zu einer Textdatei mit Stoppwörter. Stoppwörter werden ignoriert und übersprungen. In der Textdatei gilt ein Wort pro Zeile. Case-sensitiv. |
Replacement Patterns | Ersetzungsregeln, um beliebige Zeichenketten mit einer anderen Zeichenregel zu ersetzen. Eine Regel pro Zeile. Eine Regel besteht aus zwei Teilen, die mit der Zeichenfolge „|>“ getrennt werden. Die linke Seite ist ein regulärer Ausdruck (Java Regular Expression), die rechte Seite ist eine beliebige Zeichenfolge. Hinweis: Diese Ersetzungsregeln ändern nicht den eigentlichen Dokument-Inhalt, sondern beeinflussen nur das generieren neuer Metadaten, zum Beispiel: „(?i:ö)|>oe“ ersetzt das Zeichen „ö“ mit der Zeichenkette „oe“. |
Attributes | Regeln, um unter bestimmten Bedingungen Properties zu den Metadaten hinzuzufügen. Siehe nächster Abschnitt. |
Filter Patterns | Regeln aus regulären Ausdrücken (Java Regular Expression), um Matches zu entfernen. Dies wird verwendet, um False-Positives zu entfernen. Eine Regel pro Zeile. Eine Regel besteht aus bis zu drei Teilen. Die Teile werden getrennt mit <| und |> . Die drei Teile entsprechen einem „Prefix“-, „Infix“- und „Postfix“-Ausdruck von regulären Ausdrücken, die rund um einen Match angewendet werden. Treffen alle angegebenen Ausdrücke zu, dann ist die Regel aktiv und der Match wird entfernt. Z.B. die Regel John\s$<|^Joe$|>^\sDoe entfernt den Match „Joe“, wenn dieser z.B. im Zusammenhang: „His name is John Joe Doe, she said.“ vorkommt. Zur Vereinfachung können Teile der Regel auch weggelassen werden. |
Document Exclusion Rules
Üblicherweise wird jedes Dokument in einem Index mit einem konfigurierten Transformation Service transformiert. Mit dieser Regel können bestimmte Dokumente anhand von Metadaten ausgelassen werden und bleiben unverändert.

Einstellung | Beschreibung |
Metadata Name | Name des Metadatums, auf das sich die Regel bezieht. |
Exclusion Pattern | Regulärer Ausdruck (Java Regular Expression), welcher auf den Wert des Metadatums gematcht wird. Bei einer Übereinstimmung wird das Dokument nicht transformiert. |
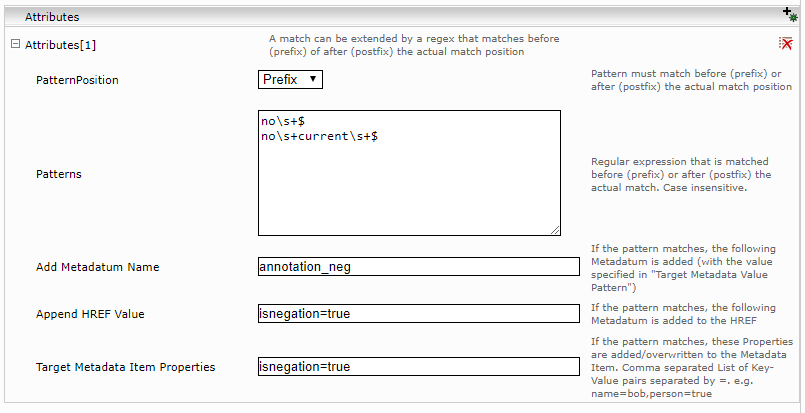
Attributes
Anhand von Regeln für reguläre Ausdrücke können Metadaten modifiziert werden, wenn der reguläre Ausdruck matcht. Dazu fügen Sie Attributes mit dem Plus-Symbol hinzu.

Einstellung | Beschreibung |
PatternPosition | Die Regel gilt unmittelbar vor dem eigentlichen Match („Prefix“) oder unmittelbar nach dem eigentlichen Match („Postfix“) |
Patterns | Liste von regulären Ausdrücken (Java Regular Expression). Ein Ausdruck pro Zeile. Die regulären Ausdrücke werden direkt vor („Prefix“) oder nach („Postfix“) dem eigentlichen Match angewendet. Stimmt ein Ausdruck überein, ist die Regel aktiv. Die Regeln sind Case-insensitive. Zum Beispiel wird die Regel „no\s+$“ beim Match „animal“ aktiv, wenn es im folgenden Kontext auftritt: „no animal was hurt.“ |
Add Metadatum Name | Ist die Regel aktiv, wird ein Metadatum mit diesem Namen erzeugt. Der Wert des Metadatums ist derselbe wie in „Target Metadata“. |
Append HREF Value | Ist die Regel aktiv, wird diese Zeichenkette an das „Link HREF Pattern“ angehängt. Hinweis: die URL muss dadurch valide bleiben. Es wird kein automatisches URL-Escaping durchgeführt. |
Target Metadata Item Properties | Ist die Regel aktiv, werden diese Properties zum Metadata Item im Vorkommnis hinzugefügt bzw. überschrieben. Die Properties werden als eine Komma-getrennte Liste von Key-Value Paaren konfiguriert, wobei die Key-Value Paare mit einem Gleichheitszeichen getrennt werden. Z.B. name=printer,person=false |
Index Konfiguration
Damit der Index den konfigurierten Service auch verwendet, muss in den Indexeinstellungen im Bereich „Item Transformation Services“ der Service referenziert werden. Klicken Sie dazu auf „Add“ und wählen Sie den von Ihnen benannten Service aus.
Es wird automatisch eine Property „launchedserviceid“ erstellt. Diese brauchen Sie nicht zu ändern.

Verwendung als ContentFilter Service
Mit der Installation des MetadataTransformationService-Plugins wird auch ein Filter Plugin „FilterPlugin.HierarchicalCsvEnricher“ registriert, welches für die Erweiterung „textcatalogenricher“ aktiviert werden kann. Navigieren Sie dazu in den Einstellungen ins „Filter“-Tab. Die Konfiguration geschieht analog zum „ItemTransformer.HierarchicalCsvEnricher“-Plugin. Es müssen folgende Metadaten im Filter-Request gesetzt werden:

Option | Aktivieren/Deaktivieren |
textcatalogenricher | Aktivieren |
FilterPlugin.MetadataOnly | Deaktivieren |
FilterPlugin.HierarchicalCsvEnricher | Aktivieren |
Aktivieren Sie die „Advanced Settings“ und fügen sie unter „Global Filter Plugin Properties“ Einstellungen für das „FilterPlugin.HierarchicalCsvEnricher – Plugin“ hinzu.
File Metadata Enricher
Dieses Kapitel beschäftigt sich mit der Verwendung des File Metadata Enrichers. Dieses Plugin ermöglicht es indizierte Dokumente (z.B.: PDF-Dateien) mit externen Quellen, wie einem XML-File oder einem CSV-File anzureichern. Dabei wird in diesem Kapitel zwischen XML File Metadata Enrichment und Catalog Settings unterschieden.
Aktivierung
Der File Metadata Enricher ist als ItemTransformationService Plugin und als PostFilter Plugin verfügbar.
Als ItemTransformationService Plugin kann dieser als ein Index Service konfiguriert werden:
Als PostFilter Plugin kann der File Metadata Enricher als ein Filter konfiguriert werden. Die Transformation passiert dann nach filtern.

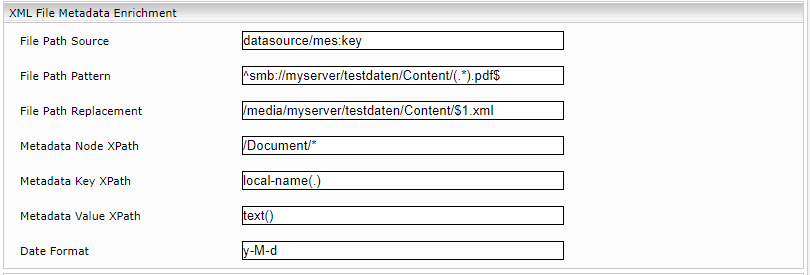
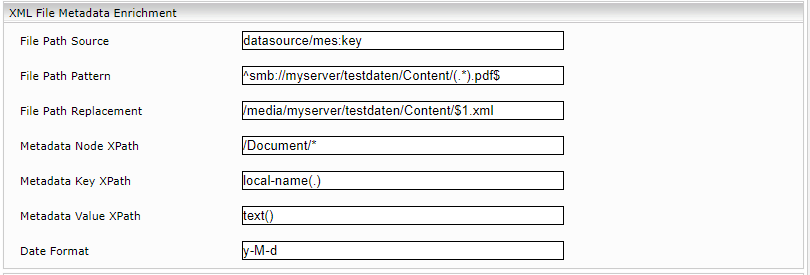
XML File Metadata Enrichment
Dieser Mechanismus ist dem Mechanismus der CSV-Transformation sehr ähnlich. Im Wesentlichen handelt es sich hierbei um die Möglichkeit, den Wert eines Metadatums mit einem Wert aus einer XML-Datei zu vergleichen. Enthält eine Datenquelle beispielsweise eine Datei mit Inhalten (z.B.: mindbreeze.pdf) und eine Datei, in der sich getrennt die zugehörigen Metadaten befinden (Bsp.: mindbreeze.xml), können diese zu einem einzigen Ergebnis zusammengeführt werden, um den Inhalt mit den Metadaten zu verknüpfen. Dieser Mechanismus wird anhand des nachstehenden Beispiels näher erläutert.
Beispiel Konfiguration:
Einstellung | Beschreibung |
File Path Source | Name eines Metadatums, welches als Quelle für die Anreicherung verwendet wird. Zum Beispiel kann ein Metadatum verwendet werden, das den Pfad des aktuellen Resultats enthält. Dies ist beim Microsoft File Connector datasource/mes:key, welches smb://myserver/testdaten/Content/ enthält. |
File Path Pattern | Schränkt den Anwendungsbereich des Enrichers ein. Alle Resultate, bei denen die mes:key-Werte nicht dem Regex aus File Path Pattern matchen, werden ignoriert (der Enricher wird nicht angewendet). |
File Path Replacement | Hier wird der Dateienpfad angegeben, wo die Metadaten der Datei enthalten sind. Die Dateien müssen dabei lokal auf der Appliance liegen oder zumindest auf dieser gemountet sein. Hier ist es möglich, einen Wert als Variable zu referenzieren, sofern dieser Wert mit dem in File Path Pattern angegebenen Regex matcht. Dabei können die matchenden Gruppen (REGEX) mit $1 aufsteigend referenziert werden (Bsp.: $1, $2, $3, …). Die Gruppe (.*) kann daher mit $1 referenziert werden. In unserem Fall wird der Name der Datei aus dem Filepath-String extrahiert, der mit dem File Path Pattern matcht. |
Metadata Node XPath | Jeder XML-Node, der durch dieses XPATH gematcht wird, wird vom Enricher als ein Objekt mit Metadaten interpretiert. |
Metadata Key XPath | Der String, der von diesem XPATH Ausdruck gematcht wird, wird vom Enricher als Name für das neue Metadatum verwendet. |
Metadata Value XPath | Der String der von diesem XPATH Ausdruck gematcht wird, wird vom Enricher als Wert des neuen Metadatums verwendet. |
Date Format | Wird hier im Java Simple Date Format ein Format angegeben, versucht der Enricher jeden String, der von Metadata Value XPath gematched wird, als Datum im Angegebenen Format zu interpretieren. Ist der String nicht im angegebenen Format, dann wird dieser vom Enricher als ein String (nicht als Datum) interpretiert. |
Beispiel:
In diesem Kapitel werden weitere Funktionen des Enrichers anhand eines konkreten Beispiels erläutert.
Konfiguration:
XML-Datei (1.xml)
<?xml version="1.0" encoding="utf-8"?>
<Document>
<UserID>4711_12</UserID>
<DocID>PDF_4711_12_CV_001.pdf</DocID>
<DocType>CV</DocType>
</Document>
Erklärung:
Das Metadatum datasource/mes:key (File Path Source) jedes Dokuments wird betrachtet. Wenn der Wert von datasource/mes:key dem Regex aus „File Path Pattern“ entspricht, dann wird der gematchte Wert mit allen lokalen oder gemounteten Filenamen aus dem Pfad von „File Path Replacement“ verglichen. Dabei wird der Dateiname, der beim „File Path Pattern“ als Regex-Gruppe definiert wurde [(.*).pdf], im „File Path Replacement“ an der Referenzstelle ($1.xml) eingefügt.
Beispiel:
Quelldatei: …/1.pdf File Path Replacement: …/1.xml
Stimmen die Pfade überein, so wird im .xml nach dem XML-Node /<Document>/* gesucht und alle Kind-Nodes des Knotens werden als relevante Information interpretiert. Der Name des Knotens wird dabei als Metadatumname für das neue, zu erstellende Metadatum interpretiert. Ist im aktuellen Kind-Node ein text() enthalten, dann wird dieser Text als Wert für das neu erstelle Metadatum gesetzt und das Metadatum wird dem aktuellen Resultat im Index angeheftet.
Beispiel:
In unserem Fall würde daher der bereits indizierten Datei „1.pdf“ folgende Metadaten angeheftet werden:
UserID: 4711_12
DocID: PDF_4711_12_CV_001.pdf
DocType: CV
Catalog Settings
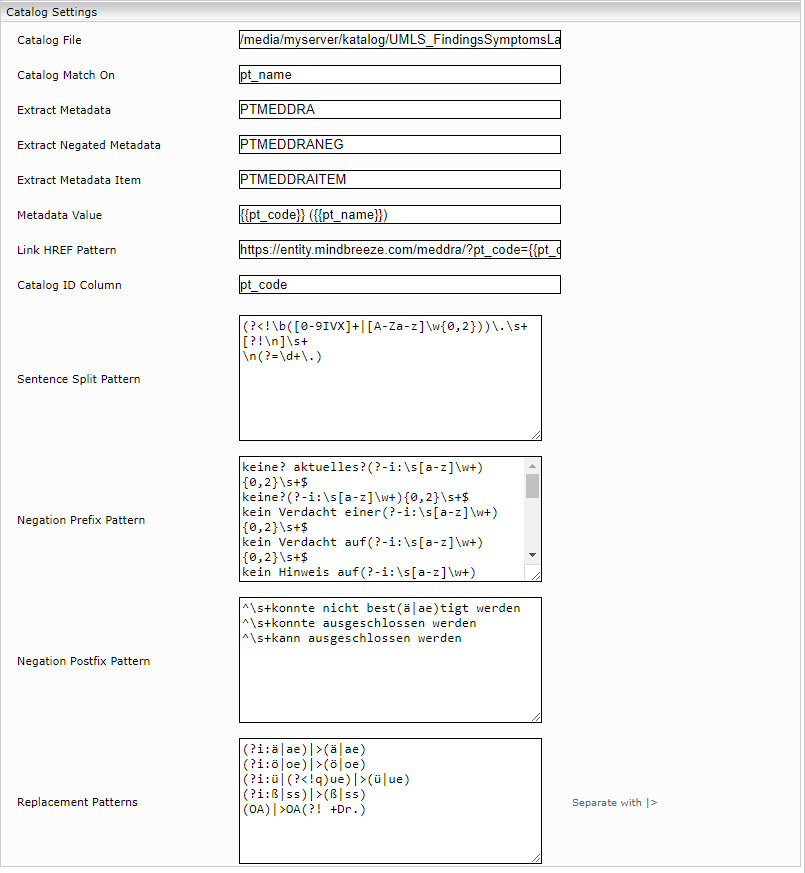
Bei diesem Mechanismus wird eine CSV-Datei wie zum Anreichern verwendet. Dabei werden, wie auch bei CSV-Transformation, Informationen aus einem Mindbreeze-Index mit dem Wert einer Spalte im CSV verglichen. Im Gegensatz zu CSV Transformation kann das Metadatum zum Vergleichen nicht gewählt werden, da das Plugin aktiv im Inhalt (content) des Files nach Übereinstimmungen sucht. Eine weitere wichtige Funktion des Plugins ist die Erkennung der Negationen. Gibt es Beispielsweise die Übereinstimmung „Nierenversagen“, und kommt in dem Text „Kein Nierenversagen“ vor, so wird „Nierenversagen“ als Negation in einem eigenen Metadatum am Resultat angeheftet. Weiters ermöglicht dieses Feature, dass automatische Links hinter den Treffern angeheftet werden und diese in der PDF-Vorschau visualisiert werden. Die detaillierte Funktionsweise dieser Funktion wird im nachstehenden Abschnitt erläutert.
Beispiel Konfiguration
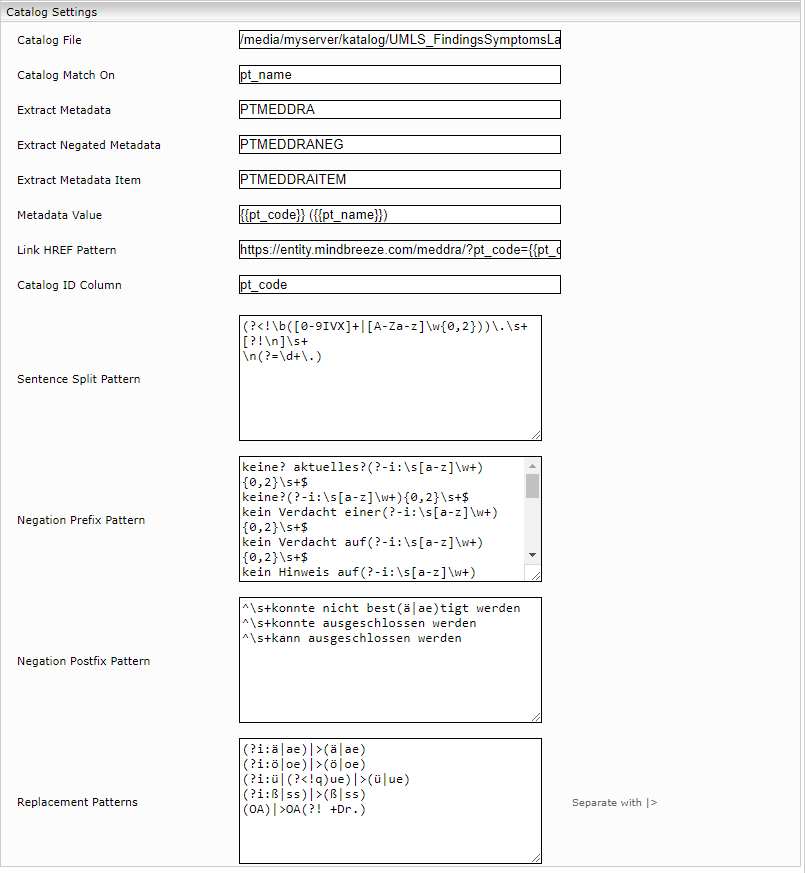
Erklärung:
Einstellung | Beschreibung |
Catalog File | Diese Einstellung beinhaltet den Pfad der CSV-Datei, die zur Anreicherung verwendet werden soll. Die Datei muss sich dabei entweder lokal auf der Mindbreeze InSpire Appliance befinden, oder auf dieser gemountet vorzufinden sein. |
Catalog Match On | Diese Einstellung gibt an, welche Spalte des CSV-Files mit der Information aus dem Inhalt der Resultate verglichen wird, um eine Übereinstimmung zu erkennen. |
Extract Metadata | In diesem Feld wird der Name des Metadatums angegeben, in welches der Text der Spalte Metadata Value bei Übereinstimmung eingefügt wird. Das Metadatum wird zum Resultat angeheftet. |
Extract Negated Metadata | Bei dieser Einstellung legen Sie den Namen des Metadatums fest, welches den Text der Spalte „Metadata Value“ bei Übereinstimmung im Falle einer Negation beinhaltet. Dieses Metadatum wird dem Resultat angeheftet. Dabei muss die Übereinstimmung wie folgt erkannt werden: Negation Prefix Pattern + Catalog Match On (String zur Übereinstimmung) + Negation Postfix Pattern |
Extract Metadata Item | Dieses Metadatum enthält eine strukturierte Form des gesamten angewendeten CSVs. Dieses Metadatum ist nicht als Filter vorgesehen und dient lediglich der Unterstützung für die Entwicklung von Insight Apps. |
Metadata Value | In diesem Feld muss der Spaltenname des CSVs angegeben werden, das in der Einstellung „Catalog File“ definierten wurde. Wenn der Wert der Spalte „Catalog Match On“ mit einem String aus dem Inhalt eines Resultates übereinstimmt, so wird dem Dokument das Metadatum mit dem Namen von „Extract Metadata“, als String mit dem Wert aus „Medata Value“, angefügt. |
Link HREF Pattern | In dieser Einstellung kann ein Link mithilfe der extrahierten Metadaten zusammengebaut werden. Dieser Link ist anschließend in der PDF-Vorschau des Clients verfügbar. Dieser Link kann vom Entwickler der Insight Apps interpretiert werden. Das Format des Links kann dabei wie folgt angegeben werden: https://entity.mindbreeze.com/?code={{pt_code}} Hierbei wird Anstelle des Platzhalters {{pt_code}} der tatsächlich extrahierte Wert, der Spalte pt_code aus dem CSV zur Invertierungszeit eingefügt. |
Catalog ID Column | In dieser Einstellung wird festgelegt, welche Spalte des CSV-Files eindeutig ist. Dies wird von Mindbreeze intern verwendet. |
Sentence Split Pattern | Diese Einstellung dient dazu, den Inhalt eines Satzes in Satzteile zu unterteilen. Der Enricher wird dabei nur bei den Satzteilen angewendet, die mit dem hier angeführten Regulären Ausdruck übereinstimmen. |
Negation Prefix Pattern | Dieses Pattern gibt den Prefix (meist Text) an, der verwendet werden soll um eine Negation zu erkennen. Bei der Syntax handelt es sich auch hier wiederum um die Syntax der Regulären Ausdrücke. |
Negation Postfix Pattern | Dieses Pattern gibt den Postfix (meist Text) an, der verwendet werden soll um eine Negation zu erkennen. Bei der Syntax handelt es sich auch hier wiederum um die Syntax der Regulären Ausdrücke. |
Replacement Patterns | Dieses Feld ermöglicht, für bestimmte Vorkommnisse von Wörten, Sätzen oder Buchstaben, Synonyme für den Enricher zu setzen. So ist es beispielsweise möglich, dass ä auch als ae interpretiert wird, oder ae auch als ä. Die Syntax dafür ist kann im folgenden Beispiel eingesehen werden: (?i:ä|ae)|>(ä|ae) Das Symbol, |>, wird als Trennzeichen verwendet. Jede Regel muss dabei jeweils in einer neuen Zeile im Konfigurationsfeld eingeben werden. |
Verwendung der neuen Metadaten
In dieser Dokumentation ist ersichtlich wie die Metadaten in der PDF-Vorschau beim Entwickeln von Insight Apps verwendet werden können: Entwicklung von Insight Apps